[논문리뷰]Sparse4D: Multi-view 3D Object Detetcion with Sparse Spatial-Temporal Fusion
- sparse 4D sampling: 3D 앵커마다 여러 개의 4D 키포인트를 할당하고, 이를 다중 시점, 스케일, 타임 스탬프 이미지 특징에 투영하여 그에 대응하는 특징들을 샘플링함
- 계층적 특징 융합: 서로 다른 시점/ 스케일, 타임 스탬프, 그리고 키포인트에서 샘플링된 특징들을 계층적으로 융합하여 고품질의 인스턴스 특징을 생성함
Intro
BEV 방식의 단점이 존재함
- 이미지 BEV 시점 변환 시에 밀접된 특징 샘플링이나 재배령을 필요로 하는데, 연산 과정이 복잡하고 비용이 많이 들어 엣지 디바이스에서 돌리기에는 부담이 있음
- 최대 인지 범위가 BEV 특징 맵의 크기에 의해 제한되기 때문에, 인지 범위의 효율성, 그리고 정밀도 사이의 트레이드 오프를 맞추기가 어려움
- BEV 특징에서는 높이 차원이 압축되면서 택스처 단서가 손실됨 따라서 BEV는 표지판 탐지와 같은 일부 인지 작업에는 부적합함
sparse4D는 시간적 문맥 융합을 접목하여 다중 시점 3D 탐지 알고리즘으로, 공간적 및 시간적 시각 단서들을 효율적이고 효과적으로 정렬하여 정밀한 3D 탐지를 달성함
- 다차원 특징들의 샘플링과 융합을 유연하게 수행할 수 있는 변형 가능한 4D 집계 모듈을 제안함
- 불량 설정 문제를 완화하기 위해 깊이 재가중 모듈을 도입함
Methodology
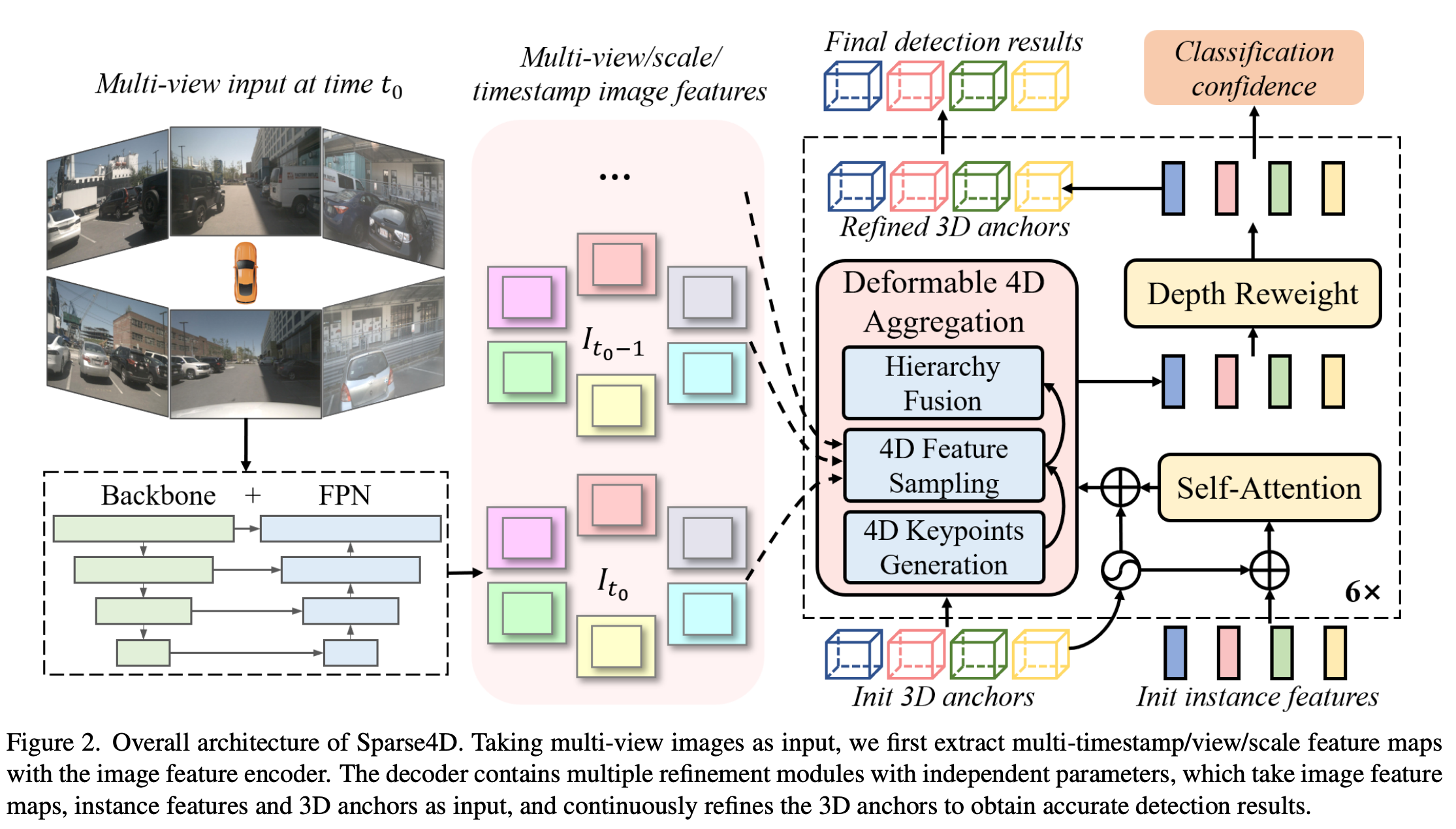
- encoder - decoder 형태
- encoder 에는 backbone(Resnet, VoVNet)과 neck(FPN)과 같은 형태로 구성됨
- 이미지가 주어지면 encoder에서 multi-view, multi-scale feature map을 구성함
- decoder: iteratively refinement(정제) 방식으로 구성되어 있음. 정제 모듈들과 최종 분류 신뢰도를 예측하기 위한 분류 헤드를 포함하고 있음
Refinement module
- Input: image feature queue(I), 3D anchor box($B \in \mathbb{R}^{M \times 11}$), instance feature($F \in \mathbb{R}^{M \times C}$)
- M: number of anchor, C: feature channel number
-
output: refined 3d box \(anchor format = \{x, y, z, \ln w, \ln h, \ln l, \sin yaw, \cos yaw, v_x, v_y, v_z\}\)
- Refinement module 에서는 self-attention을 적용하여 인스턴스간의 상호작용을 구현한다. 이때 앵커 파라미터의 Embedding이 어텐션 연산 전후로 이루어진다.
- Deformable 4D aggregation: multi-view, multi-scale, multi-timestamp, multi-keypoint 특징을 융합을 수행
- ill-posedness 문제를 해결하기 위해 depth reweights module을 적용
- regression head: GT와 anchor 사이의 오프셋을 예측함
Deformable 4D aggregation
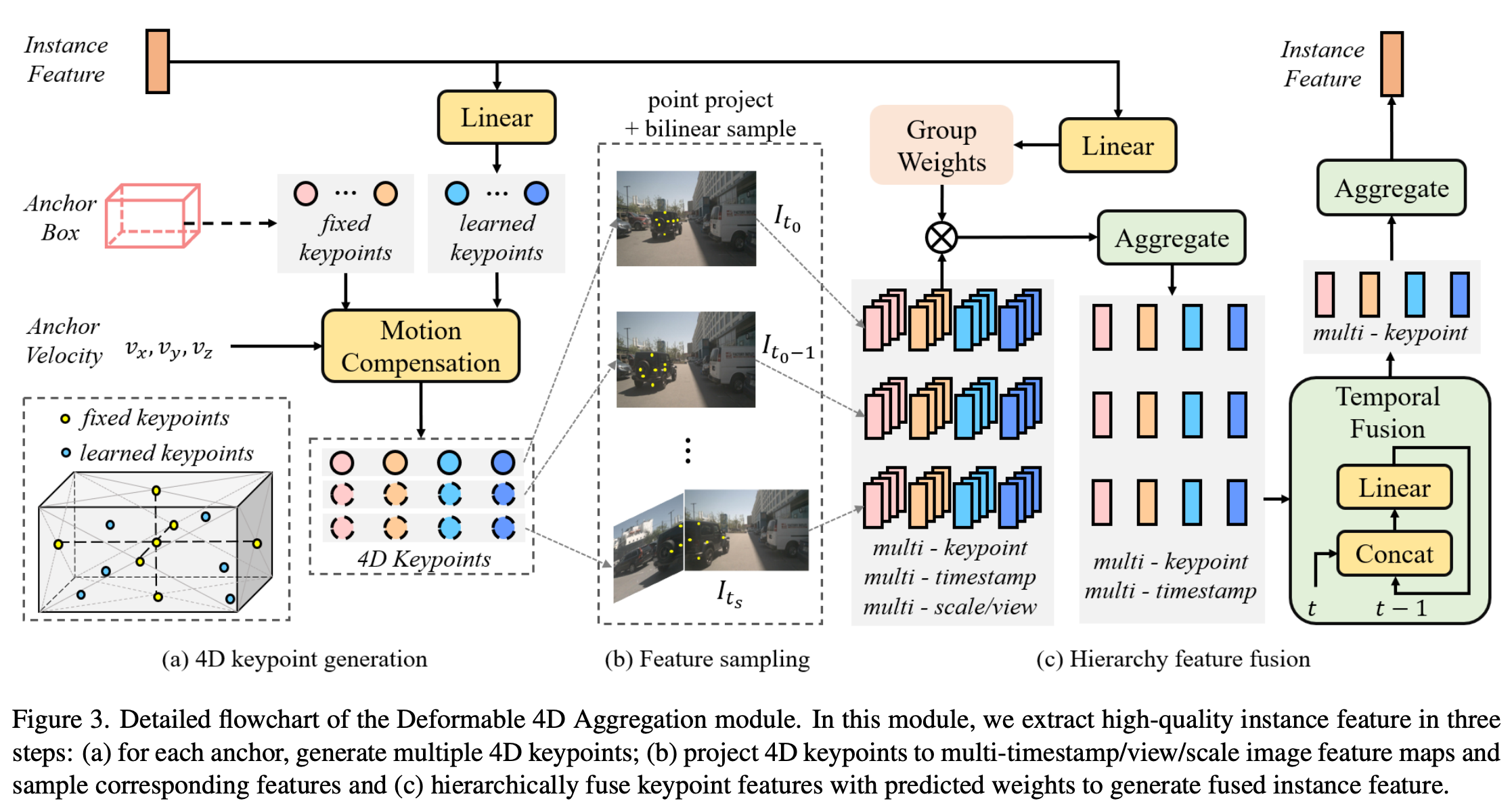
sparse feature sampling + hierarchy feature fusion 을 통한 인스턴스 특징을 획득할 수 있는 aggregation(집계) module
4D Keypoints Generation
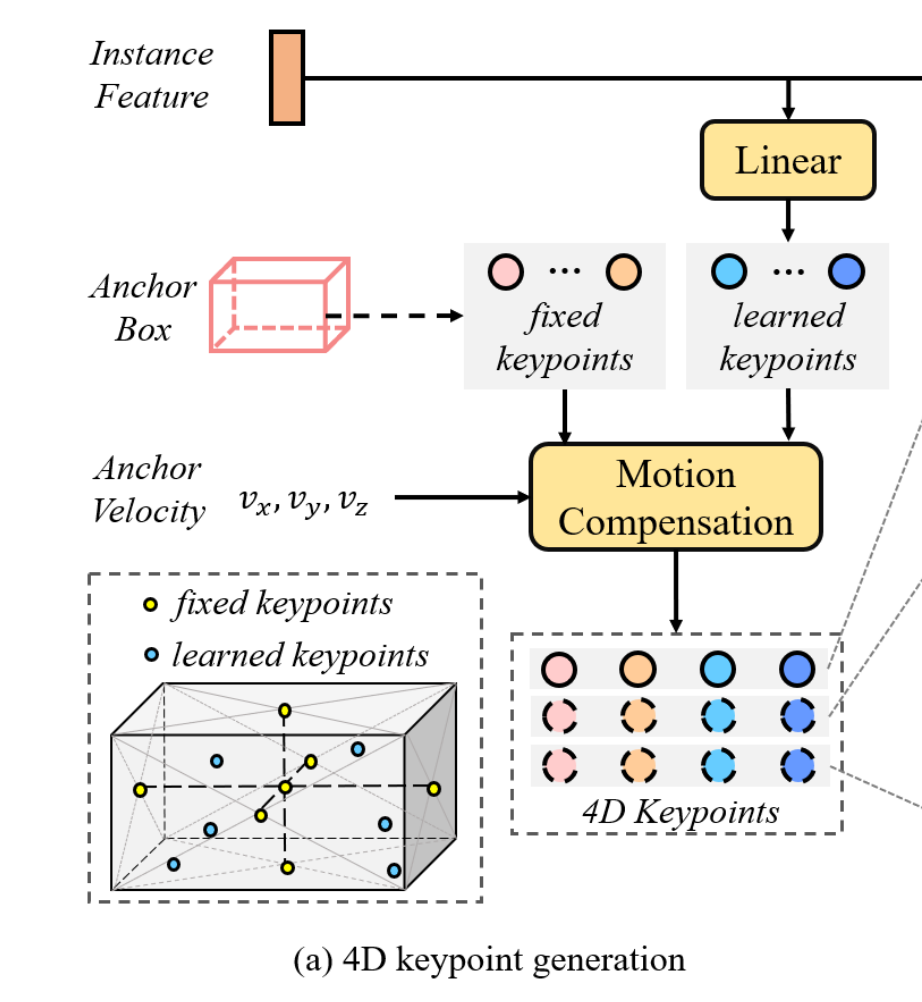
- $\text{4D keypoints} = P_m \in \mathbb{R}^{K \times T \times 3}$
- $K_F$: 고정 키포인트, $K_L$: 학습 가능한 키포인트로 구성
- $P^F_{m,t_0}$ : $t_0$ 시점에서의 고정 키포인트를 등록 3D box의 중심과 각 면의 중심을 측정함
- 학습 가능한 키포인트는 인스턴스 특징에 따라 변화하며, 이를 통해 신경망이 각 인스턴스의 대표적인 특징을 학습 할 수 있도록 함
- 학습 가능한 키포인트는 앵커 박스 임베딩이 더해진 인스턴스 특징 $F_m$이 주어졌을 때, 학습 가능한 키포인트는 아래와 같은 공식을 통해 생성됨
\(D_m = R_{yaw} \cdot [\text{sigmoid} (\Phi(F_m)) - 0.5] \in \mathbb{R}^{K_L \times 3} \quad (1)\)
\(P^L_{m,t_0} = D_m \times [w_m, h_m, l_m] + [x_m, y_m, z_m] \quad (2)\)
$R_{yaw}$는 yaw(수평 회전각)의 회전 행렬
- sigmoid: 상대적 위치 결정
- $F_m$: 인스턴스의 특징
- $R_{yaw}$: 3D의 방향 반영
constant velocity model(등속도) 을 통한 과거 $t$에서의 인스턴스 위치 정보 포인트를 구한다. \(P'_{m,t} = P_{m,t_0} - dt \cdot (t_0 - t) \cdot [v_{xm}, v_{ym}, v_{zm}]\) 이후 차량의 움직임을 고려해서 계산을 한 번 더 진행한다. \(P_{m,t} = R_{t_0 \to t} P'_{m,t} + T_{t_0 \to t} \quad (4)\)
- $R_{t_0 \to t}$: 현재 프레임에서 과거 프레임으로의 회전 행렬
- $T_{t_0 \to t}$: 현재 프레임에서 과거 프레임으로의 평행 이동
결과적으로 현재 시점의 인스턴스 포인트($P_{m, t_0}$)와 현재 시점에서의 과거 인스턴스 포인트를 계산하는 방식으로 시계열 데이터를 수집할 수 있다. 결과적으로, 아래와 같은 4D key points들을 구할 수 있다. \(P_m = {P_{m,t}}_{t=t_s}^{t_0}\)
Sparse Sampling
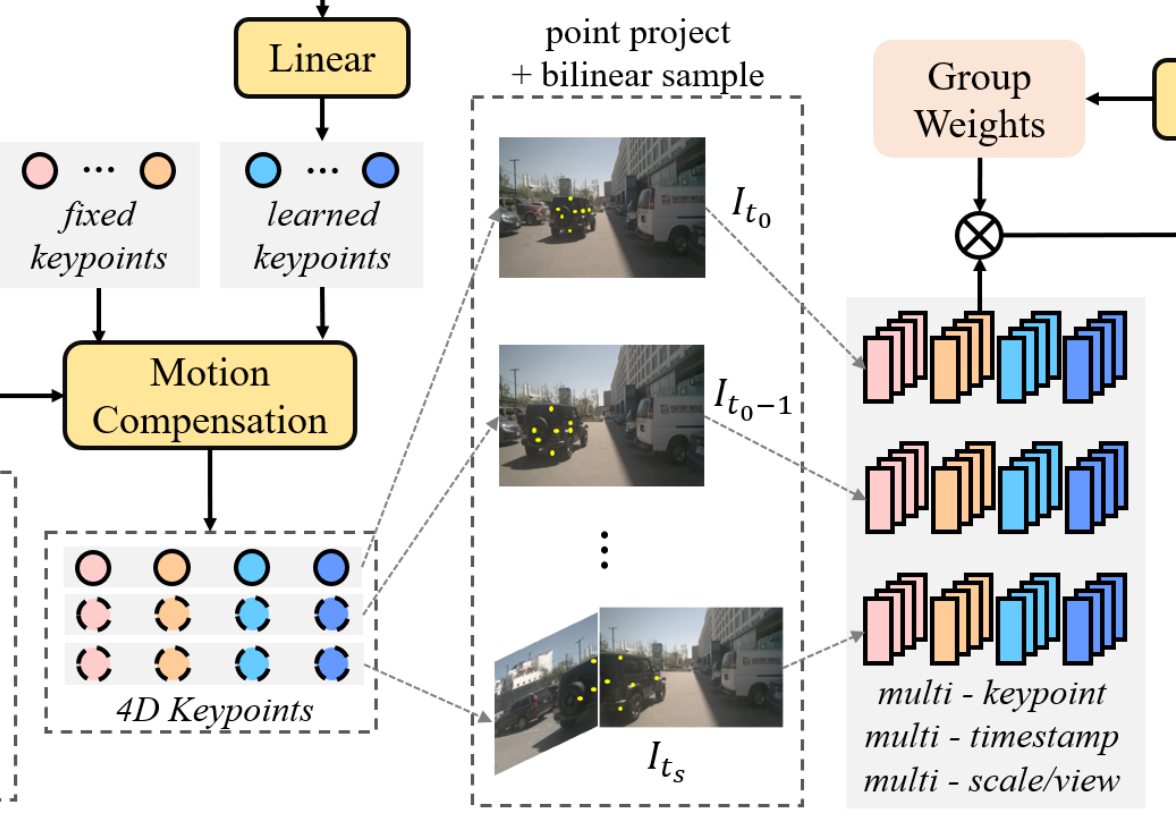
앞서 구한 4D key points(P)와 이미지 특징 맵 queue(F) 를 활용하여 효율적으로 샘플링 가능함 \(P^{img}_{t,n} = T^{cam}_n P_t, \quad 1 \leq n \leq N\)
- **$P_t$ (3D 키포인트): 이전 단계에서 운동 정보까지 반영해서 계산한 좌표
- $T^{cam}_n$ (카메라 변환 행렬):
- 이 행렬 안에는 카메라의 위치(Extrinsics)와 렌즈의 특성(Intrinsics) 정보 포함
- $n$ (카메라 번호)
- **$P^{img}_{t,n}$ (이미지 좌표)
쌍선형 보간(Bilinear)을 통해서 각 시점과 각 타임스탬프에 대해 multi-scale feature sampling을 진행한다.
\(f_{m,k,t,n,s} = \text{Bilinear}(I_{t,n,s}, P^{img}_{m,k,t,n}) \quad (6)\)
- m(anchor), k(keypoint), t(timestamp), n(camera number), s(feature map scale)
- $I_{t, n, s}$: t에 n번 카메라를 활용한 s 스케일의 feature맵을 선정
- $P^{img}$: 4D keypoint genertion에서 계산한 값 활용
- Bilinear를 통해서 이미지에서의 point 특징 계산(인접한 4개의 점을 활용, channel 모두 수행)
- $f_{m,k,t,n,s}$: 거대한 5차원 데이터
\(f_m \in \mathbb{R}^{K \times T \times N \times S \times C}\) 후보 anchor m의 다중 포인트, 타임 스탬프, 시점 및 데이터 정보가 모두 담긴 특징 벡터가 생성됨
Heirarchy Fusion
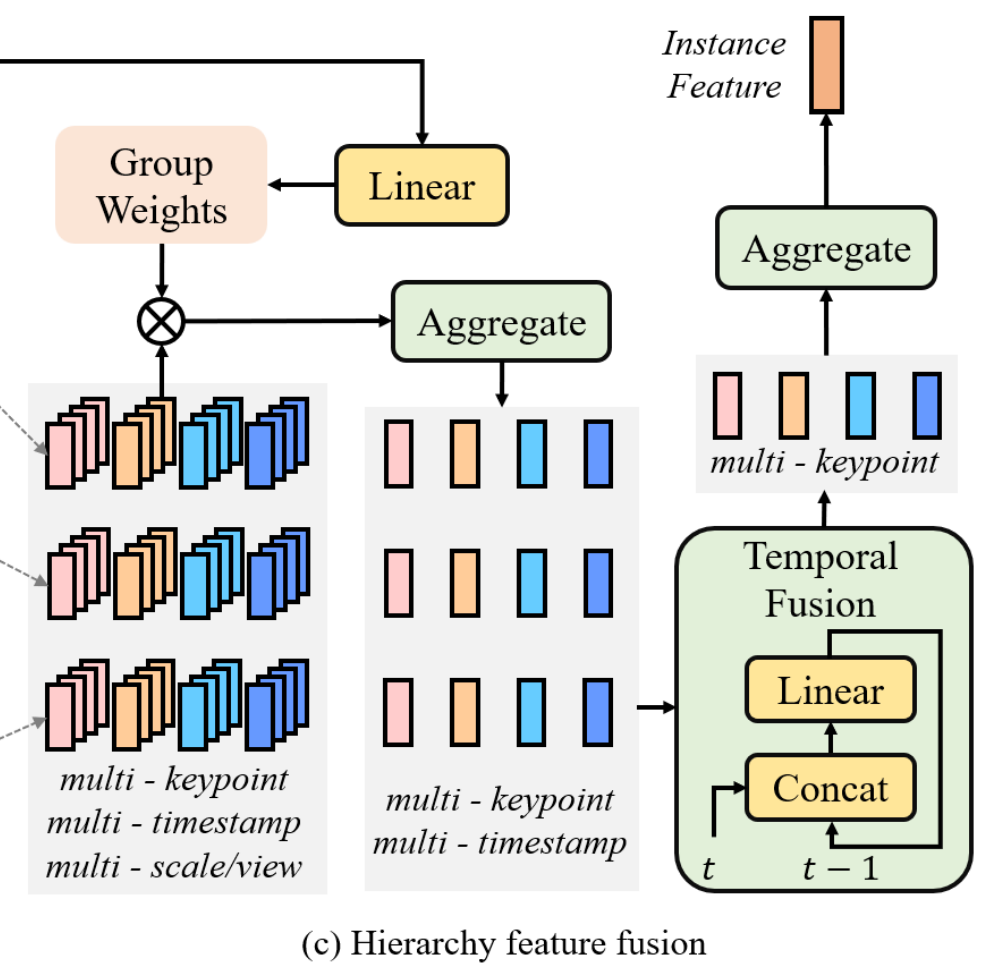
- scale, view를 aggregate: 모델 가중치를 기반으로 융합
- temporal fusion: 모델의 시계열 데이터를 sequence linear layers를 통해 시간적 융합을 수행
- keypoint fusion: 키포인트들을 기반으로 어떤 인스턴스 특징을 가지고 있는지 융합.
결과적으로 1차원 Channel vector 생성
scale & view aggregate details scale과 view에서 어떤 값들에게 높은 가중치를 매길지에 대한 가중치를 따로 생성한다. 이때 채널을 그룹으로 계산하여 계산량을 조절하고 필요한 정보를 충분히 계산하는 트레이드 오프를 선정하여 계산한다. \(W_m = \Psi (F_m) \in \mathbb{R}^{K \times N \times S \times G}\) 그룹 i 별로 가중치를 곱해서 더하여 카메라(N), 스케일(S) 차원을 줄임 \(f'_{m,k,t,i} = \sum_{n=1}^{N} \sum_{s=1}^{S} W_{m,k,n,s,i} \cdot f_{m,k,t,n,s,i}\) 이후 그룹을 연결하여 $f’_{m,k,t}$을 만듬
Temporal Fusion details
\(f''_{m,k,t} = \Psi_{temp} ([f'_{m,k,t}, f''_{m,k,t-1}])\)
- 과거의 정보들을 현재의 정보와 순서대로 혼합
- 현재 시점과 과거 시점에 대한 선형 레이어로 계산하여 통합
- 시간(T) 차원 줄임
Keypoint aggregation 앵커별 정보를 하나로 합침 \(F'_m = \sum_{k=1}^{K} f''_{m,k}\)
Depth Reweight Module
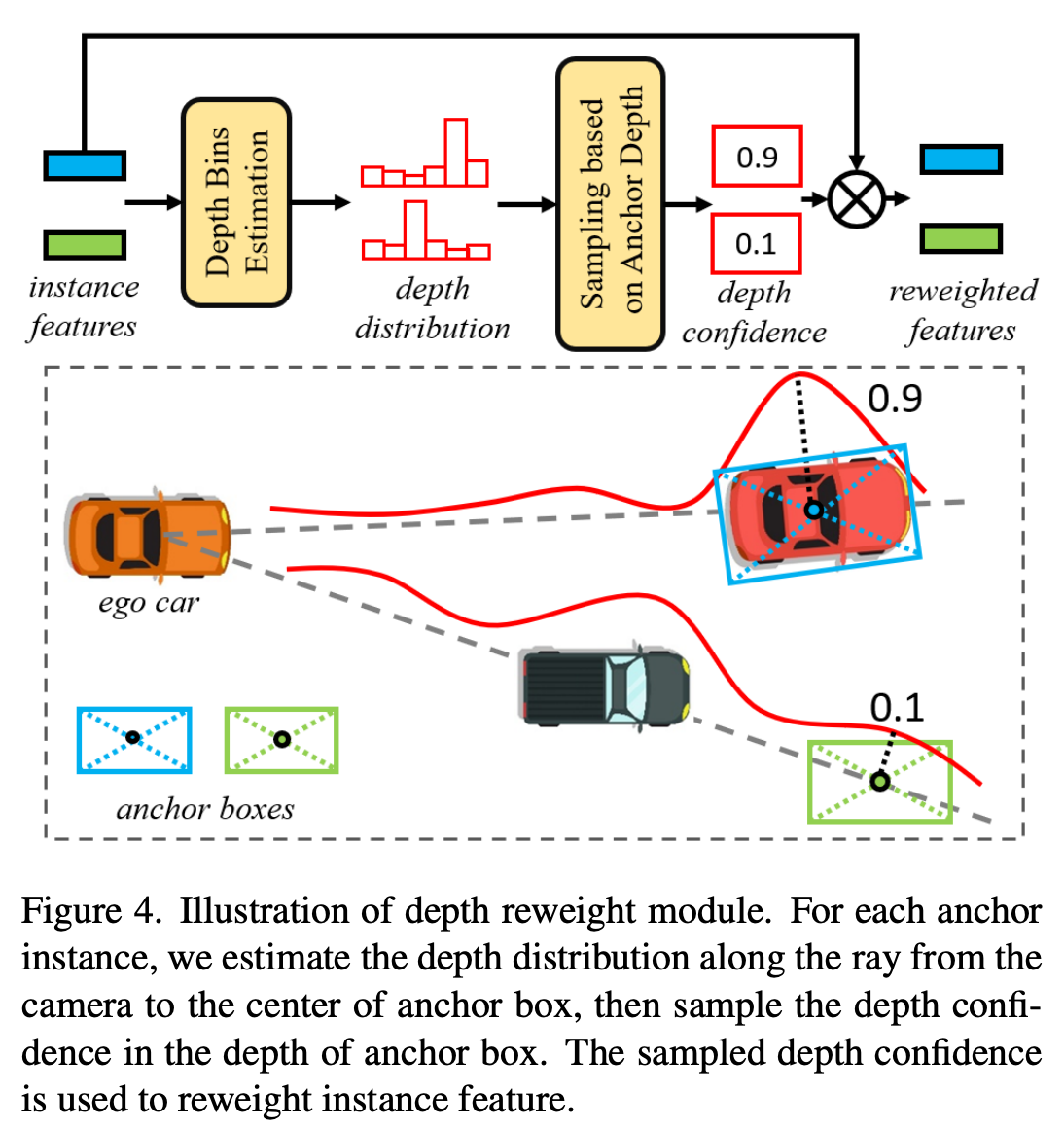
이미지를 통한 3D Detection에서 원근법의 착시에 의해 서로 다른 3D 좌표들이 똑같은 2D 좌표에 대응될 수 있다. 이 문제를 해결하기 위해 residual connections가 포함된 MLP로 이루어진 explicit depth estimation module을 도입하였음 집계된 특징에 대해 이산 깊이 분포를 추정하여 3D 앵커 박스의 깊이를 이용하여 신뢰도를 샘플링함 \(C_m = \text{Bilinear}(\Psi_{depth}(F'_m), \sqrt{x_m^2 + y_m^2}) \quad (12)\)
\(F''_m = C_m \cdot F'_m \quad (13)\) 이러한 방식으로, 2D 이미지 좌표가 정답(ground truth)과 매우 가깝더라도 3D 중심점이 깊이 방향에서 정답과 멀리 떨어져 있는 인스턴스의 경우, 해당 깊이 신뢰도는 0에 수렴하게 됨.
Training
- randomly sampled: 학습 데이터를 만들 때, 항상 0.5초 간격의 프레임만 보여주는 게 아니라, 가끔은 1.0초(2dt) 간격의 프레임도 섞어서 학습(데이터 증강 측면)
- 헝가리안 매칭: 수 많은 앵커 예측 중에서, 실제 정답을 GT당 예측 한개로 매칭 시킴. NMS 사용을 없앰
- Loss function: \(L_{total} = \lambda_1 L_{cls} + \lambda_2 L_{box} + \lambda_3 L_{depth}\)
Experiment
Datasets and Metrics
사용 데이터셋: nuScenes
- 1000개의 Scene
- 데이터 분할: train(700) / val(150) / test(150)
- scene: 20초의 비디오 (초당 2프레임)
Metrics
3D detection
- NDS (nuScenes Detection Score): 정확도(mAP)와 5가지 오차 점수(TP metrics)를 가중 평균하여 산출함.
세부 지표
- mAP (mean Average Precision): 물체의 위치(거리) 정확도 (높을수록 좋음)
- TP Metrics (True Positive Metrics): 5가지 세부 속성의 오차 (낮을수록 좋음).
- mATE (Translation): 중심점 위치 오차.
- mASE (Scale): 물체의 크기 오차.
- mAOE (Orientation): 물체의 방향(회전) 오차.
- mAVE (Velocity): 물체의 속도 오차.
- mAAE (Attribute): 물체의 속성(상태) 분류 오차.
Tracking
- AMOTA (Average Multi-Object Tracking Accuracy):
- 탐지 성능뿐만 아니라, ID가 중간에 바뀌는 오류(ID Switching) 등을 종합적으로 평가.
- AMOTP (Precision): 추적 정밀도.
- Recall: 전체 대상 중 실제로 추적해낸 비율.
Initialization
- 3D 앵커의 위치 ${x, y, z}$:
- 학습 데이터셋(Training Set)에 대해 K-평균 군집화(K-Means clustering)를 수행하여 가장 빈번하게 나타나는 물체 위치들을 초기값으로 잡습니다.
- 이유: 아무 데나 찍는 것보다, 통계적으로 물체가 자주 출몰하는 곳에서 시작하는 게 빠르기 때문입니다.
- 기타 파라미터:
- ${1, 1, 1, 0, 1, 0, 0, 0}$이라는 고정된 값으로 시작합니다. (순서대로 크기, 회전, 속도 등을 의미할 것으로 추정됨)
- 인스턴스 특징 ($F_m$):
- 무작위 초기화(Random initialization)
기본 하이퍼파라미터 설정
- 앵커 및 인스턴스 수 ($M$): 900개
- 재정제 모듈(Refinement Modules) 반복 횟수: 6회 (Layer 수)
- 특징 맵 스케일 수 ($S$): 4개 (FPN에서 나오는 레벨 수)
- 키포인트 수:
- 고정 키포인트 ($K_F$): 7개
- 학습 가능한 키포인트 ($K_L$): 6개
- 입력 이미지 크기: 640 × 1600 (꽤 고해상도)
- 백본 네트워크: ResNet101
학습 전략 (Training Strategy)
모델을 어떻게 학습시켰는지에 대한 내용입니다.
- 최적화 도구 (Optimizer): AdamW [27]
- 학습률 (Learning Rate):
- 백본(ResNet): 2e-5 (이미 잘 학습된 거라 조금만 수정)
- 나머지 파라미터: 2e-4 (적극적으로 학습)
- 학습률 감소 전략: 코사인 어닐링 (Cosine annealing) [26] (부드럽게 학습률을 줄여나가는 방식)
- 사전 학습 (Pre-training): FCOS3D [39] 모델의 파라미터를 가져와서 초기값으로 사용했습니다.
- 학습 에폭 (Epochs):
- nuScenes 테스트셋 제출용: 48 에폭
- 일반적인 실험용: 24 에폭
최적화 및 기타 (Optimization & Others)
- 메모리 절약 (Detach):
- 과거 프레임들의 특징 맵과 융합 특징($f’_t$)에 대해서는 그래디언트 계산을 끊어버립니다(detach).
- 이유: 과거 데이터까지 역전파(Backpropagation)를 다 하려면 GPU 메모리가 터지기 때문에, 과거 정보는 ‘참조’만 하고 학습(업데이트) 대상에서는 제외하는 것입니다.
- 미사용 기법:
- CBGS (데이터 불균형 해소용 샘플링 기법) 사용 안 함.
- TTA (Test Time Augmentation, 테스트 시 이미지를 돌려가며 여러 번 찍는 기법) 사용 안 함.
Ablation study
모듈 효율성
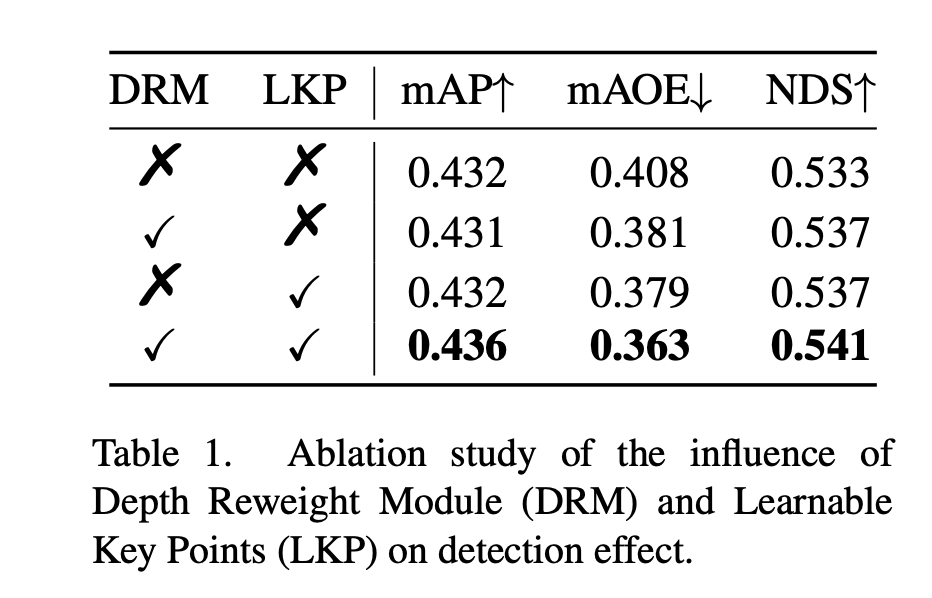
- 하나만 썼을 때: NDS가 각각 0.33%, 0.35% 상승.
- 둘 다 썼을 때: 시너지가 발생하여 mAP는 0.38%, NDS는 0.79% 대폭 상승.
motion 보정
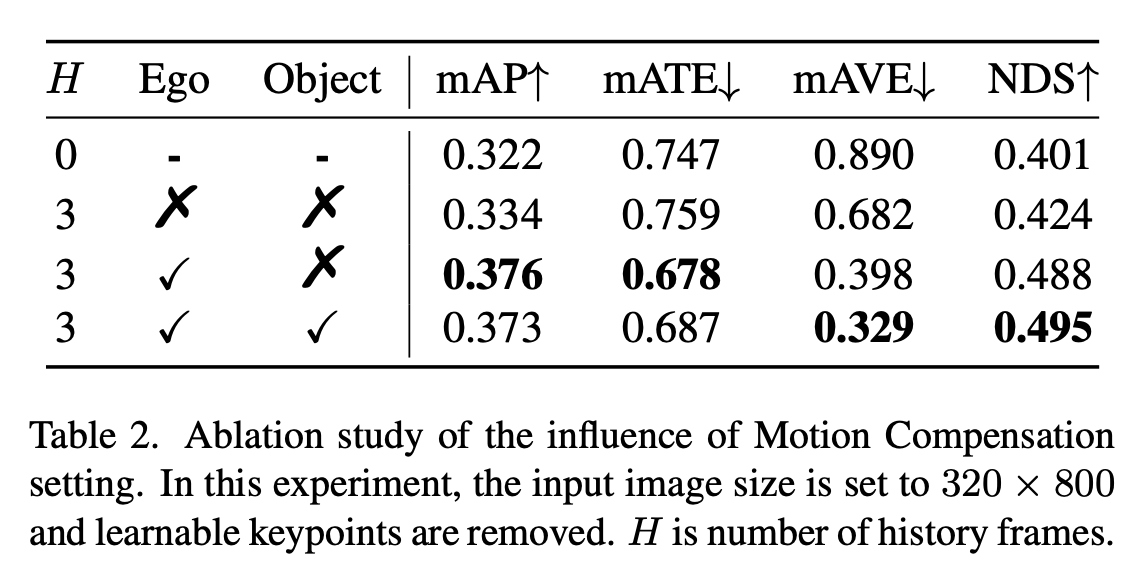
- 보정 없음 (None): 시간 정보만 단순히 추가해도 성능은 오름 (NDS +2.3%). 하지만 여전히 낮음.
- 자아 움직임 보정 (Ego Motion):
- 결과: 성능이 폭발적으로 증가. (mAP +4.2%, 속도 오차 개선 +28.4%, NDS +6.4%)
- 의미: 내 차가 움직인 만큼 좌표를 맞춰주는 게 가장 결정적입니다.
- 물체 움직임 보정 (Object Motion):
- 결과: 위치 정확도(mAP)는 비슷하지만, 속도 추정 오차(mAVE)가 6.9% 더 줄어듦. 그 결과 NDS가 0.7% 추가 상승.
- 의미: 물체의 움직임까지 고려하면 ‘속도’를 훨씬 더 정확하게 맞출 수 있습니다.
Number of Refinements
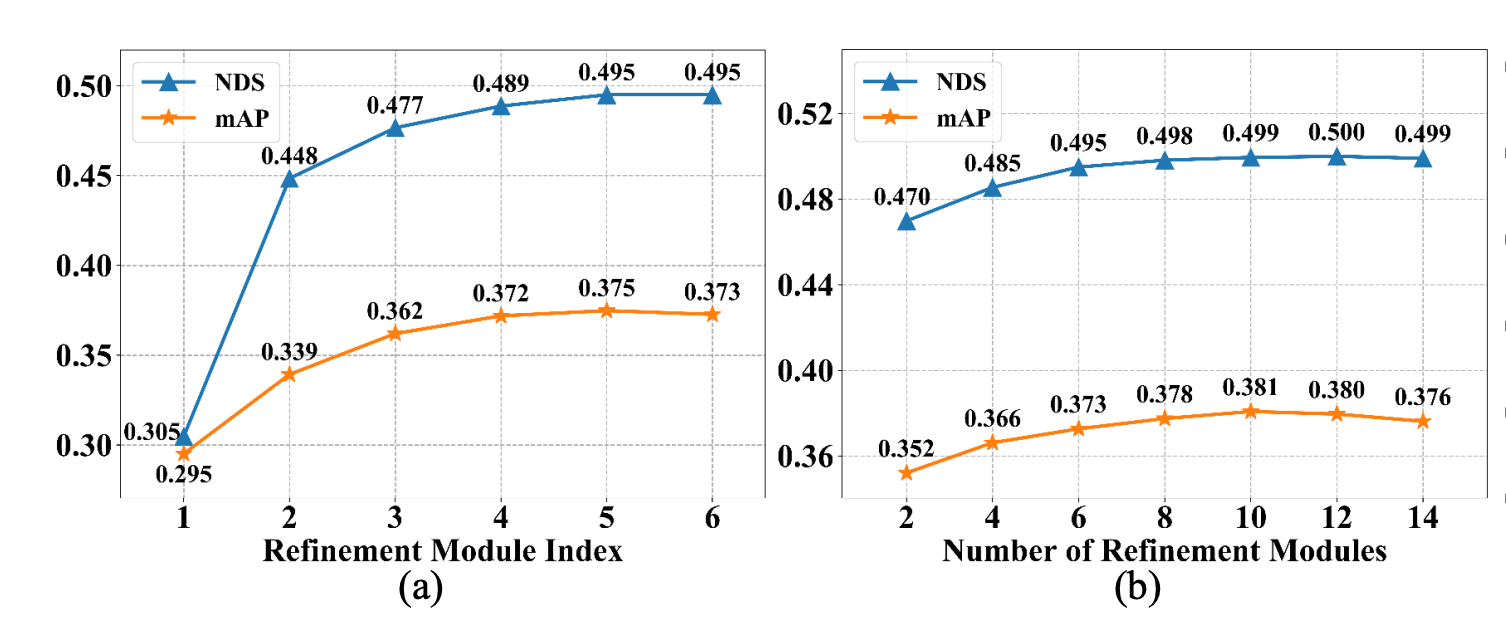
- 실험 1 (Layer별 출력): 뒤쪽 레이어로 갈수록 정확도가 오르지만, 5번째와 6번째의 차이는 크지 않음 (성능 포화).
- 실험 2 (모델별 비교): 아예 레이어 수를 바꿔가며 모델을 새로 학습시켜 봄.
- 결과: 레이어가 10개일 때 NDS 38.1%로 최고 성능을 찍음. (기본 설정은 6개 사용)
과거 프레임 수 & 하드웨어 스펙
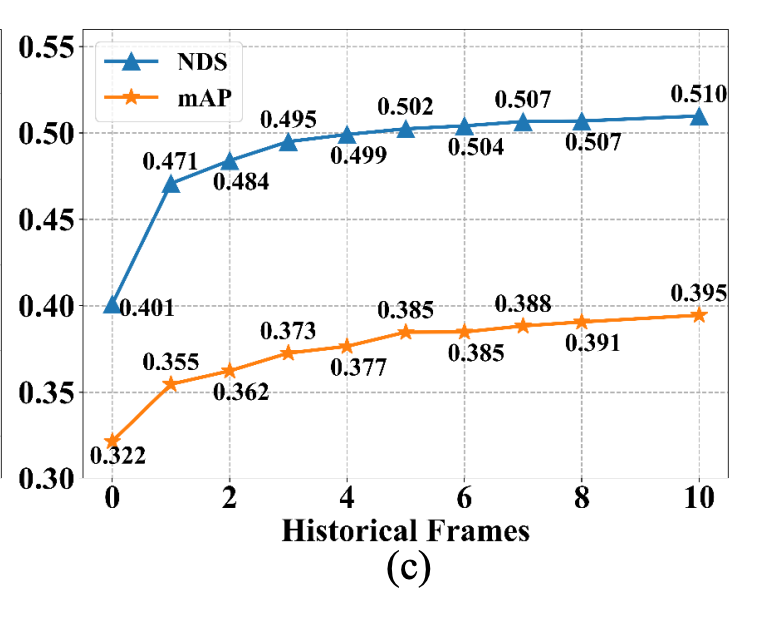
- 결과: 과거 프레임을 많이 볼수록 성능은 계속 오릅니다.
- 하드웨어 한계:
- 저자들은 더 많은 프레임을 넣어보고 싶었지만, GPU 메모리 부족으로 불가능했다고 밝힘.
- 사용된 GPU: NVIDIA V100 (32GB)
연산량 및 파라미터 효율성
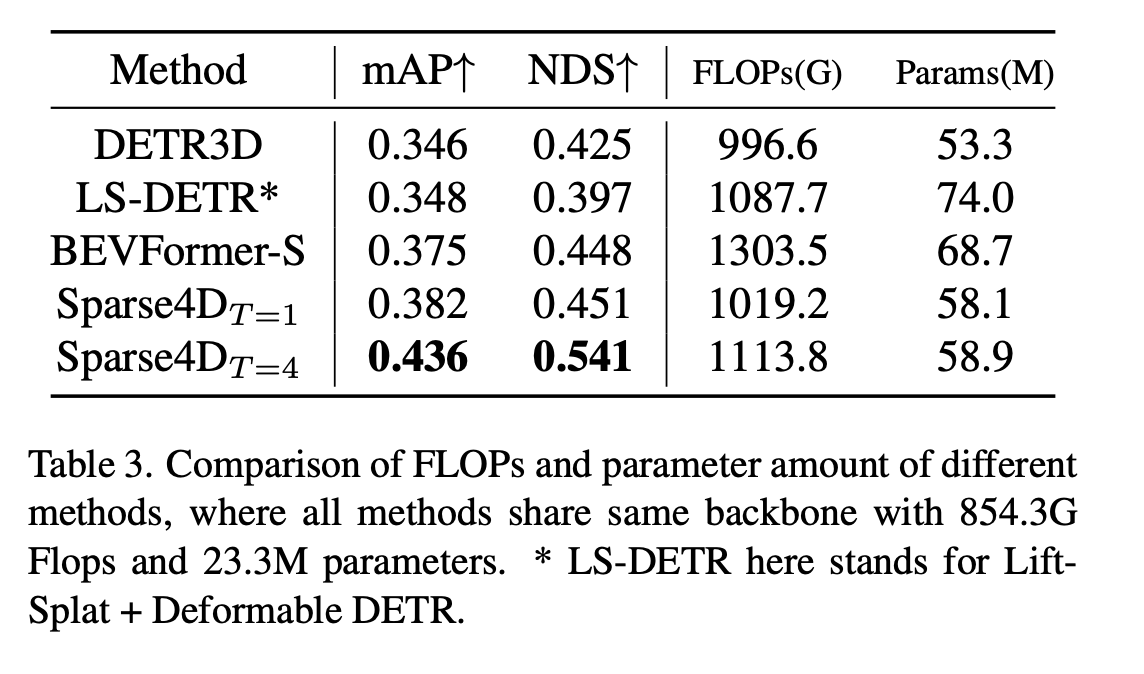
- T=1 (시간 정보 안 쓸 때):
- DETR3D와 비교 시: 연산량은 고작 2.3% 늘었는데, 성능(mAP)은 3.6% 나 더 좋음.
- BEVFormer 등 다른 모델보다 가볍고 성능이 좋음.
- T=4 (시간 정보 쓸 때 - Sparse4D의 핵심):
- 연산량은 9.3%, 파라미터는 1.4% 밖에 안 늘어남.
- 하지만 성능은 mAP 5.4%, NDS 9.0% 라는 압도적인 향상을 보여줌.
다른 모델들과의 비교
Object detection 능력 비교
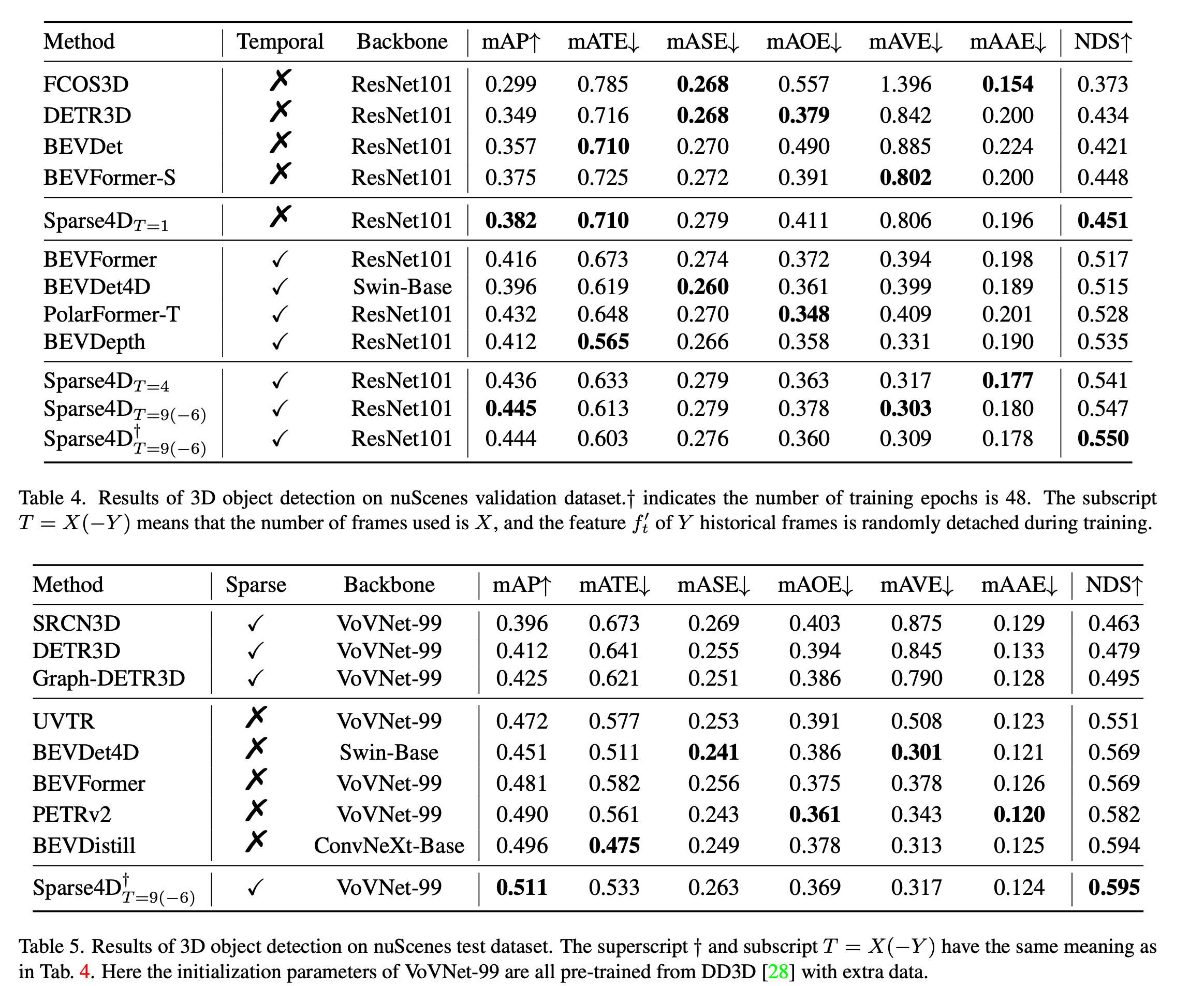
- 위에는 non-temporal model과의 비교
- 아래는 temporal model과의 비교
Tracking
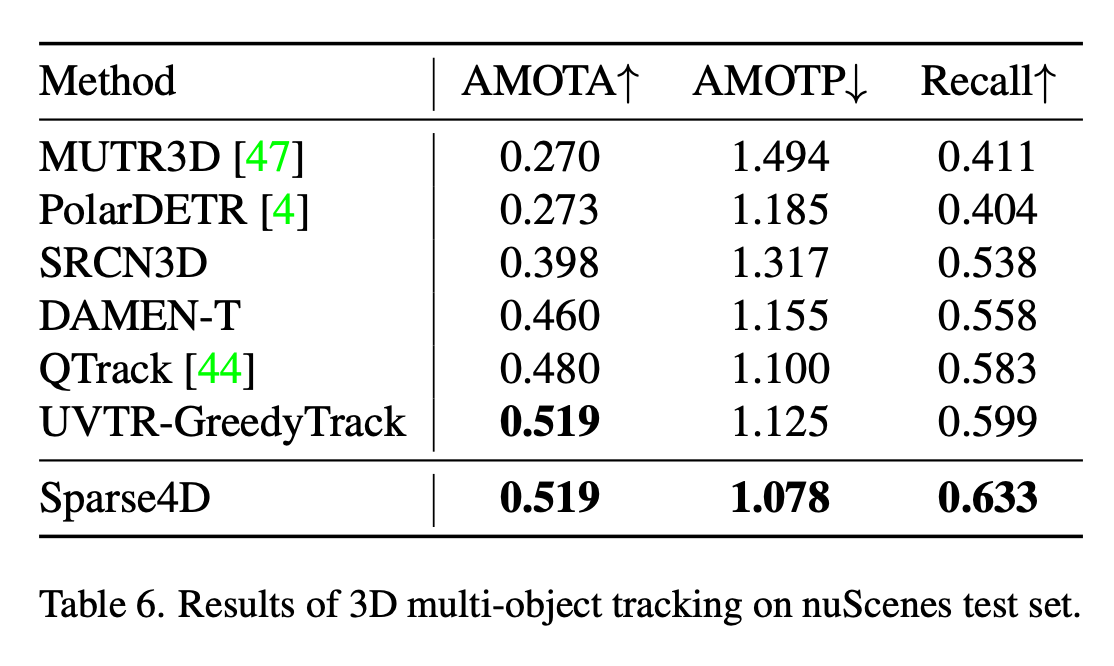
review
해당 논문은 이미지의 전반적인 특징을 활용하는 것이 아닌 Sparse 한 점들을 활용하기 위해서 노력한 것을 확인할 수 있었다. E2E로 모델을 설계하기 위해서는 모델의 크기를 경량화하고 계산의 복잡도를 줄이기 위한 노력이 필요하지만, 해당 방식은 VoxelNet과 같은 라이다 기반의 객체 탐지의 계산량 감소를 위한 sparse한 특징을 이미지에서 만들어서 구현한 방식으로 실제로 구현된 모델을 활용하고 싶다는 생각이 들었다. 해당 모델은 학습을 V100을 통해서 했다고 한 만큼, 학습은 a100으로 추론은 ai 가속기를 활용하는 방식 또는 rtx 3090으로 활용하는 방식으로 구현해서 얼마나 실시간성을 확보할 수 있을지에 대한 성능평가와 향후 수정된 v2, v3의 정확도 향상 기법들에 대해서 공부해볼 가치가 있는 방식이라고 생각된다.
댓글남기기