[논문리뷰]YOLOv11: An Overview of the Key Architectural Enhancements
YOLOv11에 대한 내용들을 정리하고 실제 사용된 모듈들의 코드를 간단하게 살펴보자.
Abstract
새로운 아키텍쳐 모듈을 도입한 버전임
- C3k2
- SPPF
- C2PSA
Introduction
YOLO 가 등장하기 전에는 2 stage 방식이 주된 방식이였음. YOLO는 이러한 흐름을 바꾼 기술 YOLOv11 부터는 다양한 컴퓨터에서 task 처리하기 위해 여러가지의 발전이 있었음
Evolution of YOLO models
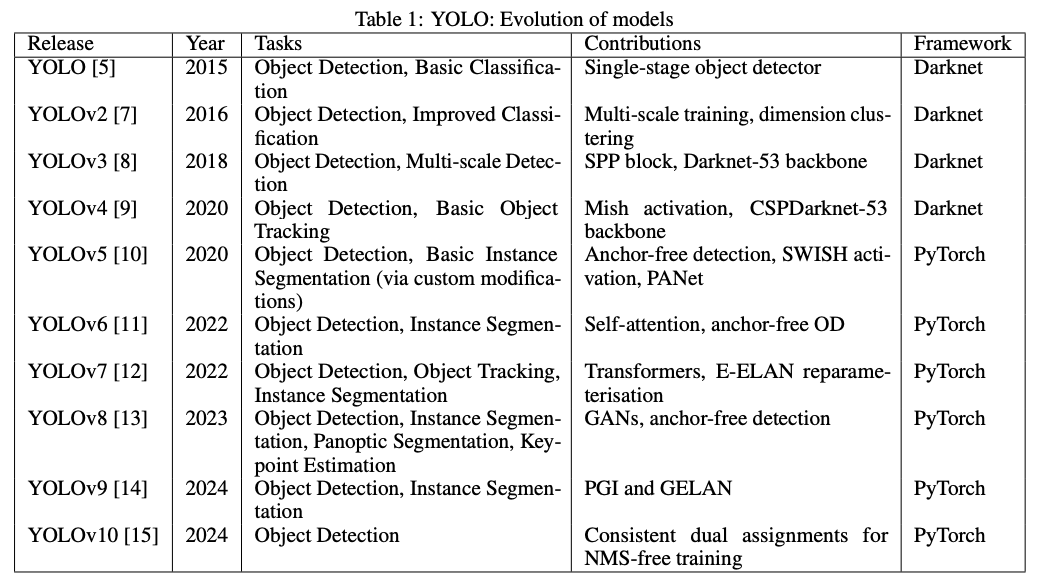
What is YOLOv11?
YOLOv11은 기존의 강점을 계승하면서도 여러가지 실시간 객체 탐지의 분야에서 적용성을 확장하는 방향으로 개선되었음 기존의 객체 탐지를 넘어 자세 추정, 인스턴스 분할 등 다양한 CV 작업을 지원함 모델의 다재다능함과 강화된 성능으로 CV의 활용 수준을 높이는 개선이 이루어짐
Architectural footprint of YOLOv11
Backbone
convolutional Layers 이전의 구조와 비슷하게 predecessors, downsampling 하는 레이어를 유지시켰다. 이러한 layer 는 특징 추출 프로세스의 기반으로 채널 수를 늘리면서, 공간 차원을 줄이는 방식이다. YOLOv11에서는 C2f 블럭에서 C3k2 블럭으로 변환하였다. CSP로 이루어진 backbone에서 컴퓨터적으로 효율성이 훨씬 높은 방식으로의 변환이다. 해당 블록은 하나의 큰 합성곱 대신 두 개의 작은 합성곱을 활용하는 방식으로 k2는 더 작은 커널 사이즈를 의미하고, 이는 처리 속도를 향상시키면서도 성능은 유지할 수 있도록 하는 방식이다. SPPF and C2PSA 이전 버전에서 사용하던 SPPF는 유지하면서, Cross Stage Partial with Spatial Attention(C2PSA)라는 기법을 적용했는데 이는 feature map에 spatial attention을 추가하는 기능으로 이를 통해서 모델이 이미지 내에 더 중요한 부분에 집중할 수 있도록 한다.
SPPF
class SPPF(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1: int, c2: int, k: int = 5):
"""
Initialize the SPPF layer with given input/output channels and kernel size.
Args:
c1 (int): Input channels.
c2 (int): Output channels.
k (int): Kernel size.
Notes:
This module is equivalent to SPP(k=(5, 9, 13)).
"""
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Apply sequential pooling operations to input and return concatenated feature maps."""
y = [self.cv1(x)]
y.extend(self.m(y[-1]) for _ in range(3))
return self.cv2(torch.cat(y, 1))
- SPPF 는 직렬적으로 5x5 의 정보 재귀적으로 사용하여 특징을 추출하는 방식
- 병렬방식보다 효율적으로 처리가 가능하다.
y.extend(self.m(y[-1]) for _ in range(3)): 이전의 출력을 재사용하여 feature map을 쌓는 과정을 통해 SPP 구성- 이를 통해
5 x 5->9 x 9->13 x 13와 같은 feature map을 직렬적으로 계산하여 효율성을 극대화 시킴
Neck
C3k2 Block C2f → C3k2 Block 으로의 변화는 feature aggregation 프로세스의 속도 향상이 이루어 질 수 있었다. 이를 통해 모델이 멀티 스케일의 정보를 효과적으로 처리 할 수 있도록 함 Attention Mechanism 모델이 이미지의 핵심 영역에 집중 할 수 있도록 하는 방식 이러한 부분은 C2PSA의 일부분으로 적용되었음
Head
C3k2 Block C3k2 블럭은 featrue map을 더 효율적으로 처리한다.
- c3k = false 인 경우 C2f 블록 처럼 동작함
- c3k = True 인 경우 C3 모듈이 사용되어 더 깊고 복잡한 특징 추출이 가능하다.
Bottleneck
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(
self, c1: int, c2: int, shortcut: bool = True, g: int = 1, k: Tuple[int, int] = (3, 3), e: float = 0.5
):
"""
Initialize a standard bottleneck module.
Args:
c1 (int): Input channels.
c2 (int): Output channels.
shortcut (bool): Whether to use shortcut connection.
g (int): Groups for convolutions.
k (tuple): Kernel sizes for convolutions.
e (float): Expansion ratio.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Apply bottleneck with optional shortcut connection."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
c_: 압축 채널의 크기(e = rateio로 0.5 인경우 절반으로 압축)self.cv1: conv layerc1의 깊이를c_깊이로 변경k[0]의 커널 사이즈,1의 strideself.cv2: conv layerc_의 깊이를c2깊이로 변경k[1]의 커널 사이즈,1의 stride- 이를 통해 계산 효율성을 극대화 시킬 수 있음
class C3f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1: int, c2: int, n: int = 1, shortcut: bool = False, g: int = 1, e: float = 0.5):
"""
Initialize CSP bottleneck layer with two convolutions.
Args:
c1 (int): Input channels.
c2 (int): Output channels.
n (int): Number of Bottleneck blocks.
shortcut (bool): Whether to use shortcut connections.
g (int): Groups for convolutions.
e (float): Expansion ratio.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv((2 + n) * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(c_, c_, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Forward pass through C3f layer."""
y = [self.cv2(x), self.cv1(x)]
y.extend(m(y[-1]) for m in self.m)
return self.cv3(torch.cat(y, 1))
- Bottleneck으로 연산을 진행하는 방식
- 2개의 conv 층으로 분할해서 처리하고 나서 마지막에 합쳐서 feature map을 만드는 방식
cv1: model로 설정되어 Bottleneck연산을 진행하는 계층cv2: 바로 마지막으로 가서 합쳐지는 계층cv3: 결과로 저장되는 feature mapy.extend(m(y[-1]) for m in self.m): cv1을 Bottleneck처리를 하도록 설정return self.cv3(torch.cat(y, 1)): 2가지의 출력을 합쳐서 하나의 Feature map으로 저장
class C3k2(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(
self, c1: int, c2: int, n: int = 1, c3k: bool = False, e: float = 0.5, g: int = 1, shortcut: bool = True
):
"""
Initialize C3k2 module.
Args:
c1 (int): Input channels.
c2 (int): Output channels.
n (int): Number of blocks.
c3k (bool): Whether to use C3k blocks.
e (float): Expansion ratio.
g (int): Groups for convolutions.
shortcut (bool): Whether to use shortcut connections.
"""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
c2f = True: 좀 더 복잡한 모듈인 c3f가 선택됨c2f = False: 좀 더 가벼운 모듈인 Bottleneck으로 특징 추출
해당 C3k2는 2개의 합성곱으로 Bottleneck을 이루고 있고, 이를 통해 빠른 추출 및 연산 효율성을 가짐. CSP Bottleneck 보다 파라미터 효율이 개선됨
CBS Blocks C3k2 block 뒤에는 CBS 층이 포함된다.
- 관련 특징을 추출하여 객체 탐지의 성능 향상
- 배치 정규화로 데이터 흐름의 안정성과 정규화 강화
- SiLU 활성화 함수로 비선형성 및 모델 성능 향상
Final Convolutional Layers and Detect Layer 각 탐지 분기는 Conv2D 계층을 통과해 바운딩 박스 좌표와 클래스 에측에 필요한 출력 수로 차원을 축소함 Detect 레이어에서는 최종 예측을 출력
- 바운딩 박스 좌표
- 객체성 점수(객체 존재 확률)
- 클래스 점수: 탐지된 객체의 클래스
Key Computer Vision tasks Supported by YOLOv11
- 객체 탐지: 이미지나 영상 프레임 내에서 객체를 식별하고 위치를 찾는 데 뛰어난 성능을 보유
- 인스턴스 분할: 객체 탐지 이상으로 이미지 내 개별 객체를 픽셀 수준까지 식별 분리할 수 있음
- 이미지 분류: 전체 이미지를 미리 정해진 카테고리로 분류할 수 있음
- 포즈 추정: 영상/ 이미지 내의 특정 포인트를 관찰하여 포즈를 추정할 수 있음
- 방향성 객체 탐지: 객체의 회전 각도를 포함해 탐지할 수 있음
Advancement and Key Features of YOLOv11
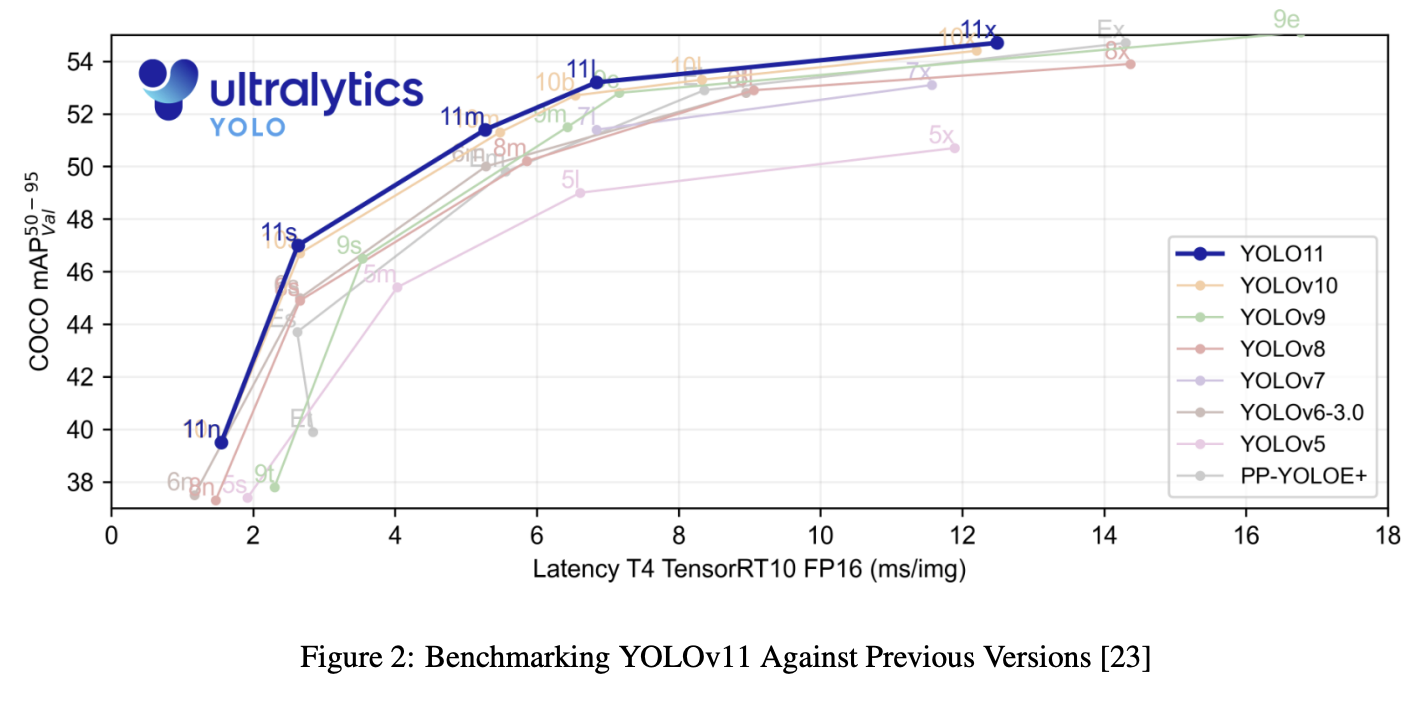
- 복잡도 절감과 정밀도 향상: YOLOv11-m 모델은 파라미터 수를 22% 줄이면서도 기존 v8보다 높은 mAP를 달성함
- 다양한 태스크에 대한 지원
- 속도 및 실시간 처리 최적화: 구조와 학습 파이프라인이 더 최적화됨
- 경량화와 확장성: 파라미터 개수를 줄이면서 성능 저하 없이 처리 속도가 빨라짐
- 밴치마크의 결과로 모든 종류의 모델에서 향상된 정확도와 더 빨라진 처리 속도를 확인 할 수 있었음
Discussion
- 효율과 확장성: 다양한 크기의 모델을 제공하여 활용도가 높음
- 아키텍처 혁신: 구조적 요소들을 잘 융합하여 객체 탐지 정확도가 향상됨
- 멀티태스크 능력: 여러가지 task에 적용할 수 있도록 변경됨
- 향상된 attention 능력: 공간적 attention이 추가되어 이미지에서 중요한 영역에 더 정확히 집중할 수 있도록 변경됨
Review & Discussion
강력한 특징추출과 최적화된 성능, 폭넓은 테스크 지원의 장점을 가지면서 산업에서도 쓰이기 좋음. YOLO는 현업에서 사용하기에 적합하다는 부분을 좀 강조하고 있었다. 성능의 향상은 이전 버전에 비해서 드라마틱하게 나타나진 않지만 여러가지의 task들을 처리할 수 있도록 하면서, 사용성의 범위가 넓어졌다는 것을 확인 할 수 있었다.현존하는 모델 중에서는 가장 실시간성이 좋다고 생각이 들지만, 아직까지도 임베디드와 같이 한정적인 자원에서의 처리 속도를 높이기 위한 과제가 있지 않을까 생각한다.
References
[2410.17725] YOLOv11: An Overview of the Key Architectural Enhancements
GitHub - ultralytics/ultralytics: Ultralytics YOLO 🚀
댓글남기기