YOLOX: Exceeding YOLO Series in 2021
Introduction
YOLOv4, YOLOv5는 anchor 기반의 Object detection에 과도하게 최적화 되어있다는 느낌이 강해서 YOLOX는 YOLOv3를 기반으로 개발을 시작하였음
YOLOX-Darknet53
Implementation Details
학습
- 300 epochs
- 5 epochs warmup
- dataset: COCO train 2017
Optimizer
- SGD(stochastic gradient descent): 미니 배치를 활용하여 loss function을 계산하는 방식
- momentum: 0.9
- weight decay: 0.0005
Learning Rate
- 초기학습률 0.01
- $lr \times Batchsize/64$: 배치 사이즈가 커지면 학습률도 그에 비례하여 선형적으로 증가시키는 규칙
- schedule: cosine lr
데이터 처리
- batch size: 128
- 8-GPU를 병렬로 연결하여 사용함
- 다중 스케일 훈련 448 ~ 832(32 strides)
YOLOv3 baseline
기준이 되는 YOLOv3모델의 구조
- Darknet53 baseline
- SPP layer 적용
- 훈련 전략
- EMA(Exponential Moving Average)
- cosine lr schedule
- Loss function
- BCE(Binary Cross Entropy)
- cls예측, obj예측, reg예측에 대한 각각의 최신 loss function을 활용함
- 데이터 증강
RandomHorizontalFlip: 이미지를 좌우로 무작위로 뒤집습니다.ColorJitter: 이미지의 색상, 밝기, 대비 등을 무작위로 변경합니다.multi-scale: 이미지를 다양한 크기로 조절하여 훈련시킵니다.
최종 성능 38.5% AP on COCO
Decoupled head
classification 과 regression 에 대한 conflict 에 대한 문제는 객체 탐지에서 주요 문제임
이에 널리 사용되는 one-stage and two-stage detector 들은 decoupled head 를 사용하고 있지만, YOLO는 여러 업데이트에도 불구하고 coupled head를 활용하고 있음
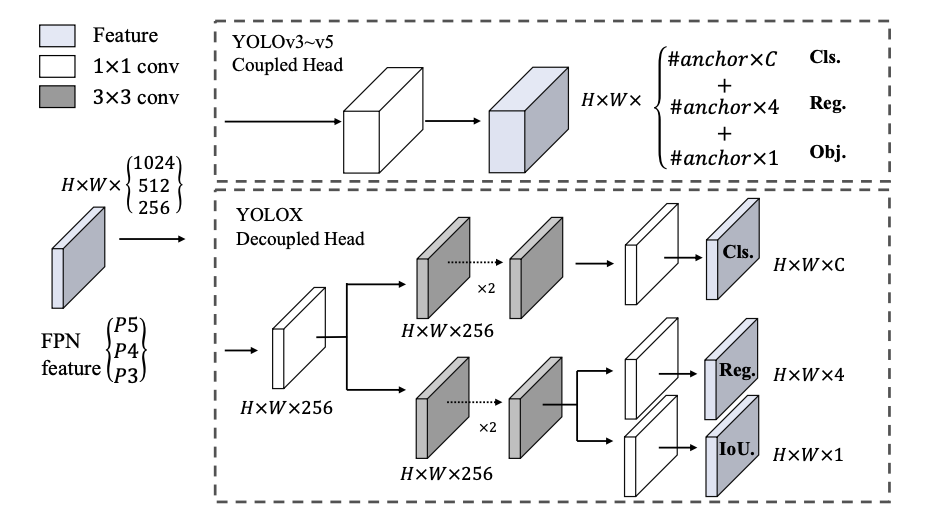
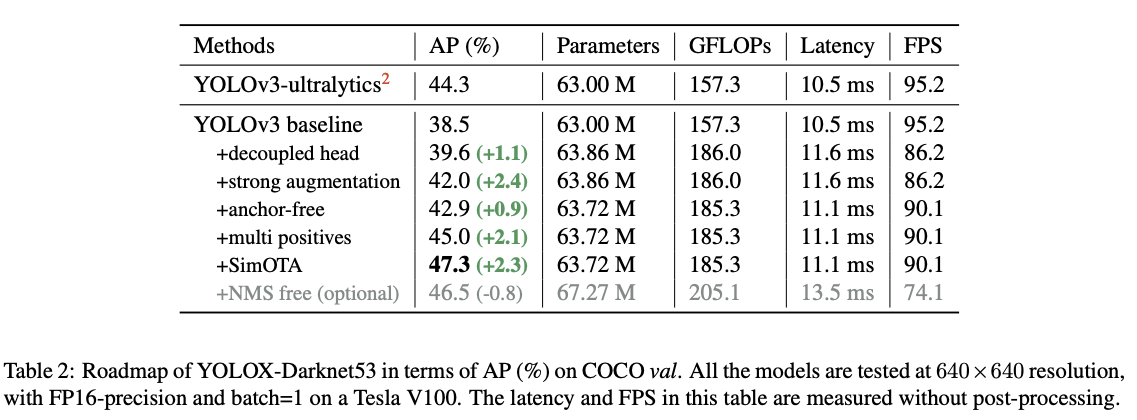
탐지 헤드를 분리하여 만든 모델에서는 latency 가 10.5ms 에서 11.6ms로 약간 증가하였음을 확인하였음.
Strong data augmentation
- Mosaic: YOLOv3에서 소개된 데이터 증강기법으로 여러개의 이미지의 부분을 겹처서 학습시키는 방식
- Mixup: 2개의 이미지를 부드럽게 섞는 증강기법
- 2개의 이미지를 일정 비율로 반투명하게 겹침
- 정답도 같은 비율로 섞음
Anchor-free
YOLOv4, YOLOv5는 모두 기존의 모델들과 같이 Anchor 방식을 동일하게 적용하였는데, anchor 메커니즘은 잘알려진 여러개의 문제가 있음
- 최적의 탐지 성능을 위해 클러스터링 분석을 수행하여 최적의 앵커 세트를 결정하는 단계가 필요함
- 그래서 특정 도메인에 특화되어있거나, 일반화 성능이 떨어진다.
- anchor mechanism 은 detection head 의 복잡한 구조를 야기한다.
- 이러한 예측 단계에서의 복잡한 구조는 edge 디바이스에서의 잠재적인 병목 현상이 일어나도록 한다. anchor-free 구조가 연구를 통해 anchor 기반과 비슷한 정확도를 보여주는 수준까지 성장하였고, 이를 활용하면 복잡했던 설계 변수를 급격하게 줄일 수 있는 장점을 가지고 있다.
YOLO에 anchor-free 적용하기 간단하게 이전에는 그리드당 3개의 앵커박스에 대한 예측을 수행했지만, anchor free를 적용하고 나서 하나의 예측만을 수행하였음 해당 4가지에 대해서만 예측을 진행하였음
- x-offset: 그리드의 왼쪽 위 모서리를 기준으로 객체의 중심이 x 좌표로 얼마나 떨어져있는지
- y-offset: 그리드의 왼쪽 위 모서리를 기준으로 객체의 중심이 y 좌표로 얼마나 떨어져있는지
- height: 객체의 높이
- width: 객체의 넓이 객체의 중심점이 있는 그리드에게 예측의 책임을 할당하고, 해당 객체의 크기에 따라 FPN(feature pyramid network) 해당하는 레벨의 layer에 책임을 할당한다.
Multi positives
anchor free 방식으로 수정하면서 객체의 중심점이 있는 하나의 칸만 긍정 객체로 판단되는 현상은 두가지의 문제를 야기한다.
- 객체 바로 옆에 있는 칸들의 유용한 학습 신호를 버리게 됨
- 이미지의 대부분이 배경으로 긍정/부정 샘플의 균형이 무너짐
이를 해결 하기 위해 FCOS: Fully Convolutional One-Stage Object Detection 에서 제시한 center sampling 을 도입하여 객체의 중심점에 해당하는 칸 뿐 아니라 주변 3 x 3 의 그리드에게도 객체 탐지의 책임을 할당하는 방식을 도입함 이를 통해 45.0%의 AP 를 달성함
SimOTA
최근 객체 감지의 중요한 발전은 advanced label assignment에 해당하는 Optimal Transport Assignment은 정답 박스(ground truth)와 예측 박스와의 라벨링시에 가장 최적의 할당이 어떻게 이루어지는지를 처리 하기 위한 방식으로 아래 4가지가 주요 특징이다.
- Global View: 개별적인 객체의 박스 만을 보는 것이 아니라 이미지 내의 모든 예측 박스와 모든 정답 박스 간의 관계를 한 번에 고려함
- 손실/품질 인식: localization 과 classification에 대한 종합적인 품질을 확인함
- 중심 우선주의(center prior): 객체 중심에서 멀어진 예측 박스는 후보에서 제거하여 계산 효율을 높이는 방식
- Dynamic number of positive anchors: 긍정 샘플을 동적으로 갯수를 조정하는 방식으로, 전체적인 적합도가 높으면 여러개의 긍정 샘플을 적용한다. 반대로 전반적으로 낮은 적합도를 보이면, 소수의 긍정 샘플을 적용함
그러나 Sinkhorn-Knopp algorithm 적용시에 25% 정도 증가한 학습 시간이 걸려 Simplify OTA를 제작하여 적용했음
[!note] SimOTA
- $c_{ij}$: 총 비용. 값이 낮을수록 좋은 후보
- $L_{ij}^{cls}$: 예측 j가 정답 i의 클래스를 얼마나 정확하게 맞추었는지. 틀릴수록 높은 값
- $L_{ij}^{reg}$: 예측 j가 정답 i의 regression을 얼마나 정확하게 맞춰었는지. 틀릴수록 높은 값
- $\lambda$: 균형 계수. 분류 손실과 위치 손실 중 어느 것을 중요하게 여길지 정하는 가중치
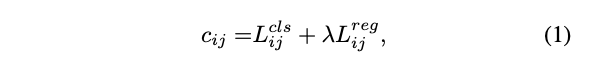
긍정 샘플 선택 과정
- 중심 주변의 고정된 영역안에 있는 예측들만 후보로 추가함
- 각 후보들의 cost 값들을 계산하고 상위 k개의 후보를 추림
- k개의 긍정 샘플을 가지고 있는 후보들은 모두 긍정으로 레이블됨 나머지는 모두 부정으로 래이블링
k개의 긍정 샘플을 할당하는 과정에서 중요한 점은 k 는 유동적으로 변한다는 점이다. 이러한 SimOTA를 통해서 학습시간을 줄일 수 있었고, 추가적으로 Sinkhorn-Knopp algorithm을 사용하는데 필요한 하이퍼파라미터 설정없이 사용할 수 있었음
결과적으로 SimOTA를 적용함으로써 45.0% -> 47.3% 정도의 AP를 얻을 수 있었음
End-to-End YOLO
End-to-End 방식을 구현하기 위해서 3가지의 방식을 구현해보았음
- 1:1 label 매칭 방식
- head에 2개의 convolutional layer을 추가함
- stop gradient 1:1로 매칭된 것을 제외한 라벨에 신호가 흐르지 않도록 함 이 3가지의 변경점을 적용하고 나니 추론 속도와 성능의 작은 감소가 나타났음
Other backbone
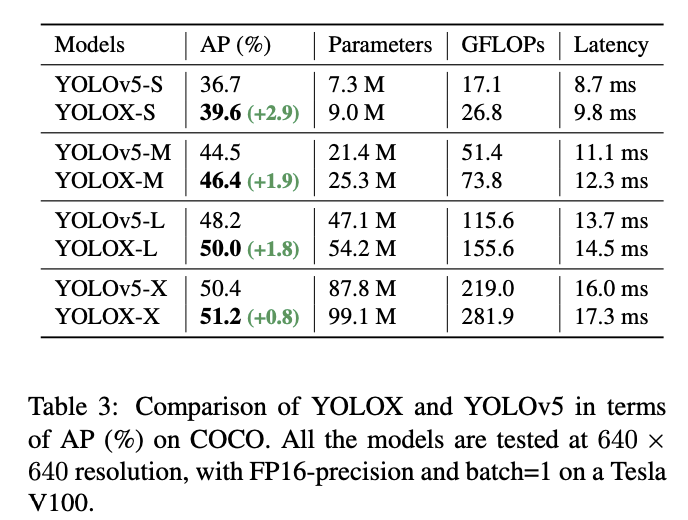
YOLOv5와 동일한 구조로 구성한후 주요 개선점인 Decoupled Head, SimOTA가 얼마나 성능을 향상시켜주는지를 확인해보고자 했음 채택한 YOLOv5의 구성요소
- Modified CSPNet: 특징 추출을 담당하는 메인 백본 네트워크
- SiLU activation: 모델의 비선형성을 더해주는 활성화 함수
- PAN head: 다양한 크기의 특징들을 융합하여 탐지 성능을 높이는 넥(neck) 구조
해당 모델의 구조를 따라가면서 경량 모델도 생성하고 이전의 정확도를 비교해보았음
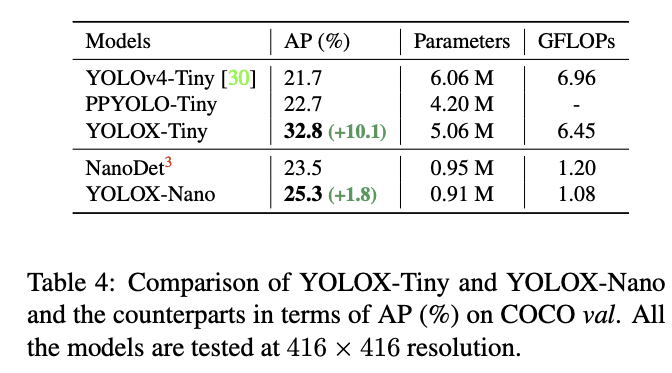
해당 경량 모델과 대형 모델에서 데이터 증강을 활용하였으나 MixUp 데이터 증강을 통해서는 큰 모델만이 정확도 향상을 얻을 수 있었고, 경량 모델에서는 오히려 정확도가 감소하는 효과를 얻었음
Comparison with the SOTA
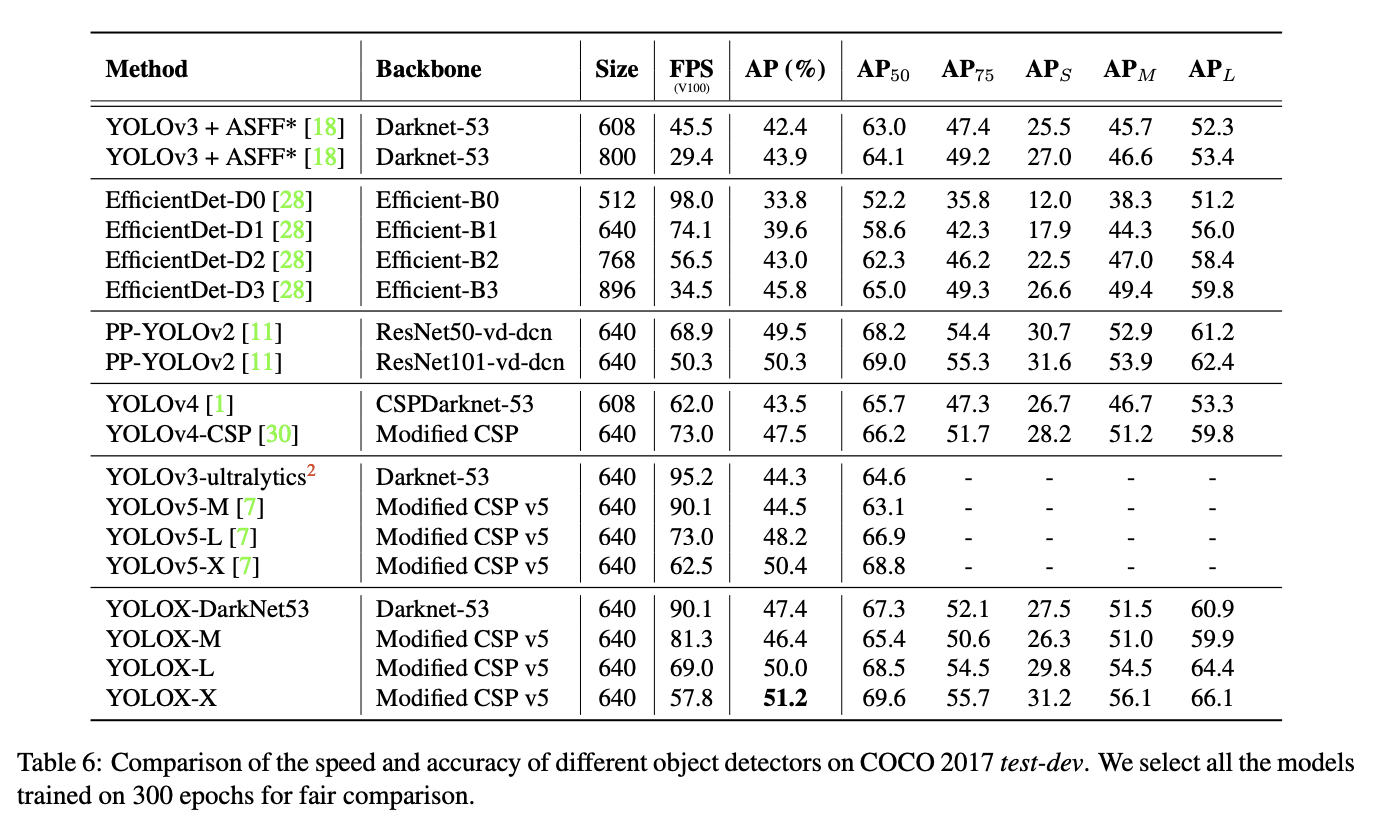
Review & Discussion
이전의 YOLO 버전에서 활용했던 anchor 방식의 단점을 없애기 위해 anchor-free 구조를 통해 예측의 복잡도를 줄이는 방식이 효과적이엿다는 부분이 인상깊었다. 해당 부분은 이전과 다르게 anchor-free 방식의 선행연구가 성공적이였으다는 것을 포함하지만, 해당 선행연구의 문제점을 해결하기 위해 Multi positives 방식을 통해 학습 신호의 손실을 최소화 하는 방식을 사용한 것이 좋은 연구 방식이었다고 생각한다.
그리고 대다수의 인공지능과 관련된 연구는 학습시간의 중요도 보다 예측의 중요도를 평가하는 경우가 많은데, SimOTA는 학습의 시간과 효율성을 고려한 방식이라는 점에서 다른 연구들과 다르게 효율성과 사용성을 고려하는 연구방식임을 확인할 수 있었다.
근본적으로 YOLO는 객체 인식을 위한 하나의 방식이지만, 이 방식이 널리 사용되고 개발자들이 많이 적용을 검토하는 이유가 실제 사용성과 개발 편의성을 고려해서 연구를 진행한다는 점이 큰 장점이지 않을까..?

댓글남기기