You Only Look Once: Unified, Real-Time Object Detection
Abstract
- frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities.
- 객체 검출하는 방식에서 차이를 두는 방법 → 객체 바운더리 박스를 검출, 클래스 문제를 하나의 회귀 문제로 정의
Introduction
- 단일 convolution network로 여러 바운딩 박스와 그에 해당하는 클래스의 확률을 예측한다.
강점
- 매우 빠른 예측 속도
- 실제 Titan X 그래픽 카드를 활용해서 45fps 이미지 처리 가능했다.
- 더 빠른 버전은 150fps 이미지 처리 가능했음
- 이 실험 결과를 바탕으로 실제 스트리밍 video 를 25ms의 속도로 처리할 수 있음을 알 수 있음
- 2배 높은 정밀도: real-time system보다 2배 빠른 정밀도를 가지고 있음-real-time systems
- 이미지에 대한 전역적인 처리
- sliding window나 region proposal-based 방식과 다름
- 전체 이미지를 트레이닝과 테스트에 사용함으로써 문맥적인 정보를 더 정확하게 분류할 수 있음
- Fast R-CNN은 large context에 대한 정보가 없어서 배경을 객체로 오분류하는 경우가 많음
- YOLO는 이러한 부분을 절반으로 줄였음
- 일반화 가능한 객체 표현을 학습함
- 자연 이미지로 학습후 artwork 대상으로 테스트를 진행한 결과 다른 탐지 방법보다 큰 차이로 성능이 뛰어남
- 일반화가 매우 뛰어나게 되어있어 YOLO는 새로운 도메인이나 예상치 못한 input에 대한 처리가 용이함
Unified Detection
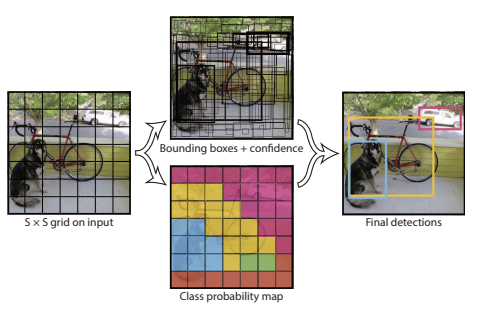
입력 이미지: S x S 의 그리드 셀로 나눈다. “Each grid cell predicts B bounding boxes and confidence scores for those boxes.” (각 그리드 셀은 B개의 바운딩 박스와 그 박스에 대한 신뢰도 점수를 예측한다.) 이때 각 그리드 셀은 자신의 영역 내에 있는 어떤 객체의 중심점이 위치하는지를 탐지할 책임을 가지게 된다. 그리드 셀에서는 B 개의 바운딩 박스를 예측한다. 신뢰도 점수: 바운딩 박스에 객체가 포함되어 있음을 얼마나 확신하는지 + 상자가 예측하는 개체가 얼마나 정확하다고 생각하는지
\[Confidence = Pr(Object) * IOU^{truch}_{pred}\]- Pr: object가 박스안에 있을 확률
- IOU(Intersection Over Union): 박스 안에 객체가 존재한 경우, 예측된 바운딩 박스와 실제 정답 박스가 얼마나 겹치는지를 나타내는 값
[!note] bounding box
- x, y: center 좌표
- w: width
- h: height
각 그리드 셀에서 클래스에 대한 조건부 확률을 통해서 점수를 매긴다. 하지만 해당 그리드 셀이 B개의 바운딩 박스가 상관없이 해당 그리드 셀은 하나의 클래스 확률로 계산한다.
\[SCORE = Pr(Class_i|Object) * Pr(Object) * IOU^{truch}_{pred} = PR(Class_i) * IOU^{truch}_{pred}\]-
$Pr(Class_i Object)$: 객체가 i 클래스일 조건부 확률 - $Pr(Object) * IOU^{truth}_{pred}$ : 신뢰도 점수(바운딩 박스에 객체가 포함되어 있으면서, 상자가 예측하는 객체가 얼마나 정확하다고 생각하는지)
이에 따라 결과적으로 YOLO 모델은 $S \times S \times (B * 5 + C)$ tensor로 인코딩 된다.
Network Design
- Convolution 모델로 구현하였음
- Pascal VOC detection dataset으로 평가함
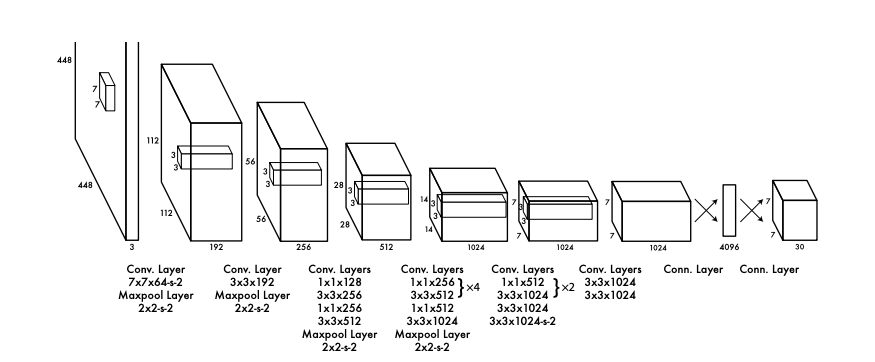
Initial convolutional layer(특징 추출부)
- 이미지에서 특징을 추출
- GoogLeNet model에서 영감받아 구성했음
- 24개의 Convolution layer + 2개의 Fully Connected Layer 로 구성되어있음
- GoogLeNet 의 Inception Module: 1 x 1, 3 x 3, 5 x 5의 합성곱 계층으로 여러 특징 추출하는 방식
- Network In Network : 1 x 1, 3 x 3의 합성곱 계층 활용하는 방식
- YOLO
- 1 x 1: 축소 계층, 공간적인 특성보다 맵이 깊이(채널 수)를 줄여주는 압축의 역할
- 3 x 3: 압축된 맵을 받아 실질적인 공간 특징을 추출하는 역할
fast YOLO: 24 layer 가 아닌 9 layer 로 설계됨
network를 학습시킬때 convolution Layer에는 ImageNet classification시에 224 x 224를 활용한다. 많은 양의 데이터를 효율적으로 학습시키기 위해서 저해상도를 활용함 fine tuning: Fully connected layer까지 포함해서 객체 추출을 함 이때는 해상도를 2배로 올려서 실행한다.
Training
Pretrain
- 처음에는 20 Convolution Layer를 통해서 학습시켰음
- 이때 Imagenet 2012 validation set을 통해서 학습시켰을때 상위 5개의 단일 crop에 대해서 88%의 정확도를 가지게 되었음
Perform detection
- pretrain 되어있는 모델에서 무작위 weight 로 초기화된 4개의 convolution layer와 2개의 fully connected layer를 추가하였음
- 이후 해상도를 2배로 올려서 train을 진행함 (224 x 224 → 448 x 448)
final layer
- 두가지의 정보를 담고 있음
- class probabilities
- bounding box coordinates:
- 이미지의 height 와 width를 기준으로 정규화하여 0~1사이의 값으로 설정
- bounding box의 height, width나 x, y좌표또한 정규화를 진행함
활성화 함수
- 마지막 층은 linear Activation Function을 사용함
- 마지막 층을 제외한 층에서는 leaky reLU를 사용함
- $\phi(x) =\begin{cases}x, & \text{if } x > 0 \0.1x, & \text{otherwise}\end{cases}$
- reLU와 다르게 음수이더라도 미세하게 신호가 살아있어 뉴런이 완전히 죽는 것을 방지할 수 있는 장점이 있음
손실함수
- SSE(Sum Square Error)를 사용함
- localization error와 classification error에 동일한 가중치를 적용하는 방식으로 이상적이지 않음
- 대다수의 셀이 객체가 없어서 물체가 포함된 셀의 신호를 덮어버리는 현상이 생길 수 있음
- 이를 해결 하기 위해 bounding box coordinate에 대한 loss를 증가 시키고, confidence predictions for boxes that don’t contain object에 대한 loss를 감소시키는 방식으로 바꾸었음
- 따라서 2개의 파라미터가 추가됨
- $\lambda_{coord} = 5$
- $\lambda_{noobj} = .5$
- 큰 상자와 작은 상자의 오차 중요도 오류
- 큰 상자에서의 2픽셀은 그렇게 큰 오차가 아니지만 작은 상자에서의 2픽셀은 큰 오차임을 적용해야 하는 문제
- 이를 제곱근 값을 통해 구하는 것으로 loss값을 정확하게 적용 할 수 있었음

- 이는 제곱근 함수는 x 가 클 수록 기울기가 가파르고, 작을 수록 기울기가 완만하다는 성격을 활용한 풀이 방법이다.
- 예측기
- yolo는 하나의 cell에 B개의 bounding box를 가지게 되는데 이때 2개의 box모두 예측을 하는 것이 아닌 그중 하나만을 선정해서 예측을 진행함
- 이때 하나의 cell당 2개의 예측기가 있다고 생각할 수 있는데 훈련시에는 2개중 IOU점수가 높은 box에서 책임지고 학습한다.
- 이를 통해서 해당 cell의 예측기가 학습하게 되면 해당 클래스에 대한 전문화가 이루어진다.
- 전문화를 통해 각 예측기가 서로 다른 임무를 수행하는 예측기로 학습된다.
- 모든 정보를 포함한 loss function:

- $1^{obj}_{ij}$: object가 i 번째 cell에 j 번째 bounding box에 존재하면 1, 아니라면 0
- 첫번재 줄: 바운딩 박스 중심 좌표(x, y) 오차 (중요도 적용을 위해 가중치를 곱해줌 = 5)
- 두번째 줄: 바운딩 박스 크기 오차 (중요도 적용을 위해 가중치를 곱해줌 = 5)
- 세번째 줄: 객체가 잇는 박스의 신뢰도 오차
- 네번째 줄: 객체가 없는 박스의 신뢰도 오차 (중요도 적용을 위해 가중치를 곱해줌 = 0.5)
- 다섯번째 줄: 클래스 분류 오차
[!note] 트레이닝 정보 및 결과 횟수: 130 epochs train dataset & validation dataset: PASCAL VOC 2007, 2012 batch size: 64 momentum: 0.9 decay: 0.0005 learning rate schedule:
- 처음 몇 애포크 동안 학습률을 0.001 ~ 0.01까지 서서히 올림
- 이후 모델이 안정화 된 후 0.01 학습률로 75애포크 동안 훈련을 계속함
- 학습률을 0.0001로 낮춰 마지막 30애포크 정도를 학습함 overfitting 방지:
- dropout 적용: 첫번째 connected layer에 0.5 적용
- 데이터 증강 적용: 원본 이미지 크기의 최대 20%까지 무작위 스케일링 및 변환, 노출과 채도도 1.5배까지 무작위로 조정
Inference
분류기 기반 설계와 다르게 YOLO는 하나의 네트워크로 예측하기 때문에 비교할 수 없이 빠른 장점을 가지고 있다. 또 그리드 설계는 bounding box 예측에 공간적 다양성을 적용한다. 그러나 큰 객체의 경우 여러개의 그리드에 포함되어 있을 수 있다. 이 경우에는 Non-Maximum Suppression(NMS) 로 하나의 객체를 가르키는 여러 개의 중복된 박스중에서 신뢰도 점수가 가장 높은 하나만을 남겨두는 방식으로 mAP가 2~3%정도 향상되었다.

Limitaions
- 그리드 구조는 해당 그리드 마다 하나의 클래스만을 가질 수 잇으므로 YOLO는 공간 제약을 가지고 있음.
- 이러한 공간 제약 때문에 그룹으로 나타나는 작은 개체에 대해 탐지가 어려움(ex. 세때
- 데이터에서 bounding box를 예측하는 방식이므로 새롭거나 특이한 종횡비를 가지는 객체에 대한 탐지가 어려움
- 입력 이미지에서 여러 개의 다운샘플링 레이어를 가지고 있어 바운딩 박스를 예측하는데 rough 한 기능을 가지고 설계됨
- bounding box에 대한 좌표 오차는 작은 박스와 큰 박스를 동일하게 취급하기 때문에 IoU에 영향을 준다.
- yolo에서 처리하고자 하는 주요 오류는 박스 위치에 대한 오류임.
Comparison to Other Detection Systems
Deformable parts models
- 파이프라인이 여러개로 분리되어 있는 구조
- sliding window를 활용한 방식
R-CNN
- region proposal: 물체가 있을 법한 bounding box를 찾아주는 모듈을 활용
- 각각의 단계가 시간이 꽤 걸리는 작업임
- bounding box 를 검출하여 상자에 점수를 매기는 방식은 비슷하지만, 공간적 제약을 통해 YOLO는 비교적 적은 개수의 bounding box를 제안한다.
Other Fast Detectors(fast R-CNN etc)
- R-CNN의 속도에 중점을 맞춘 모델
- Selective Search를 활용하기 보다, 컴퓨팅 파워와 neural network를 사용하여 속도를 높인 모델
- 그러나 실제로는 30hz
Deep MultiBox
- 하나의 convolution network를 사용하지만, 하나의 class 만 분류할 수 있음
OverFeat
- sliding window방식의 검출, 분리된 환경
- localization에 최적화되어있음, 검출에 최적화되어있지 않음
MultiGrasp
- YOLO의 그리드 방식의 영감이 된 방식
- 객체 검출보다는 영역 탐색의 성향이 강한 방식
Experiments
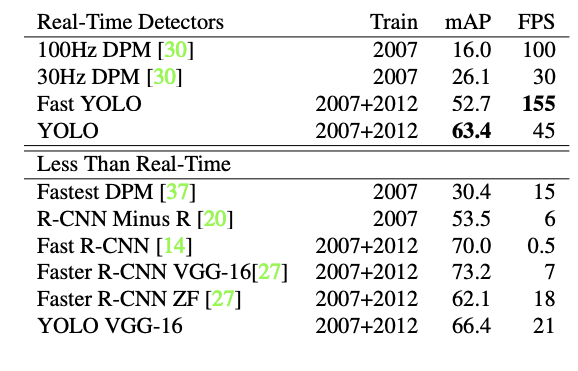
Comparison to Other Real-Time Systems
Fast YOLO
- 52.7% mAP -> Other Real-Time Systems 보다 2배 정밀도
YoLo
- 실시간 성능은 유지하면서 63.4%의 mAP 확보
YOLO + VGG16
- 정확도는 올라가지만 속도가 현저히 느려짐
Fast R-CNN
- Selective search를 활용해서 bounding box를 생성하는 방식으로 2초 정도 걸려서 정확도는 높지만, FPS가 0.5로 매우 낮음
Faster R-CNN + VGG-16
- Selective search의 느린 속도를 극복하기 위해 neural network를 사용하는 방식으로 설계된 모델에서는 정확도는 유지했지만, 여전히 느린 속도를 가지고 있음
VOC 2007 Error Analysis
Darek Hoeim 의 객체 탐지 오류 분석 툴을 그따라서 가장 mAP가 높은 Fast R-CNN과 비교하여 분석해보면

- Correct
- Localization: correct class와 비교했을 때 0.1 <= IoU < 0.5
- Similar: 비슷한 class의 경우 IoU <= 0.1
- Other: IoU <= 0.1로 겹치지만, 다른 클래스인 경우
- Background: 어떤 클래스와도 IoU < 0.1인 경우
YOLO는 Localization에 대한 오류가 가장 많이 나타남, 반면 Fast R-CNN의 경우는 13.6%의 오류율로 가장 많이 나타남
Combining Fast R-CNN and YOLO
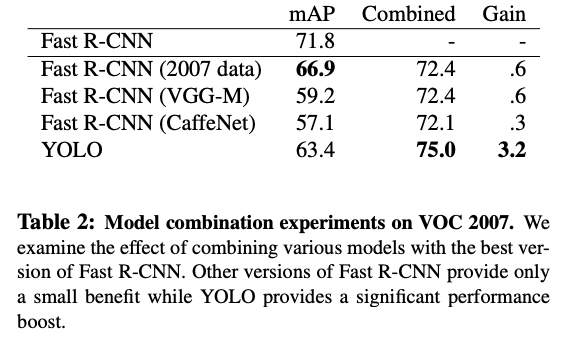
Fast R-CNN이 정확도가 가장 높은 점을 활용해서 Fast R-CNN과 YOLO에서 검출하는 bounding box를 비교하여 비슷한 2개의 box를 IoU에 비례해서 가산하는 방식으로 결합하여 사용하면 mAP가 75.0%까지 올라갈 수 있다. 2개의 모델을 따로 돌려서 비교한 후에 결과가 나오는 방식이므로 정확도는 높아지지만, 속도의 이점은 살리지 못하는 방식
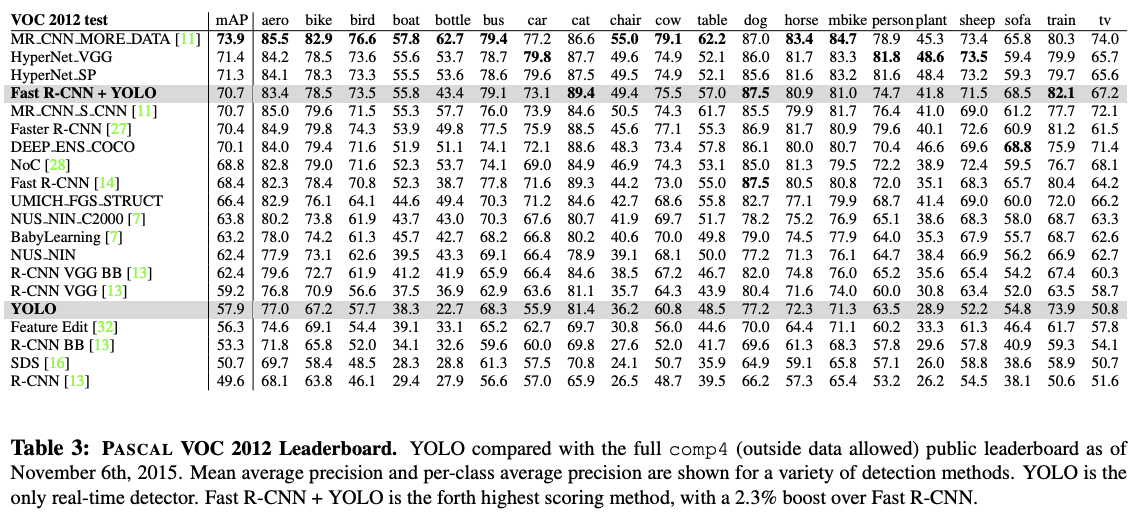
VOC 2012 Result
Generalizability: Person Detection in Artwork
일반화 성능을 측정하기 위해 피카소 데이터셋과 사람-예술 데이터 셋을 활용하였음
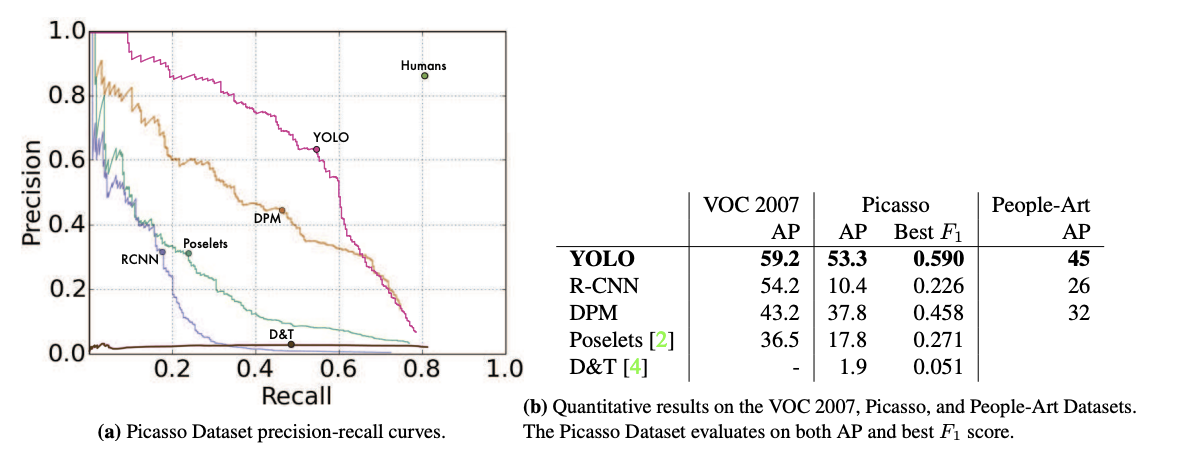
R-CNN, Poselets등과 같은 모델은 피카소나 People-Art 데이터셋에 대해서는 AP 가 낮아졌지만, DPM, YOLO 두개의 모델은 높은 AP를 유지하였다. 이를 통해 YOLO가 다른 모델들보다 좋은 일반화 성능을 가지고 있음을 확인할 수 있었음.
Review & Discussion
YOLO는 이전의 객체 검출과 다르게 하나의 Convolution network를 통해서 객체 검출을 구현하기 위해서 고려된 모델이다. 이를 위한 노력들을 볼 수 있는 논문이였다. 2가지의 task를 하나의 네트워크로 예측한다는 점은 네트워크의 구조를 단순화 함으로써 예측의 속도를 높일 수 있는 방법임을 확인할 수 있었다.
하나의 네트워크 구조를 구현하기 위해서 2가지의 task를 분리해서 고려한 후에 결과를 합치는 방식과 그리드 방식을 통해서 탐지한 객체에 대한 책임을 가진다는 개념 보면서 책임을 분리했던 부분이 탐지 속도를 높일 수 있는 좋은 방법이였다고 생각된다.
그리고 연구진들이 섬세하게 구성했다고 생각한 부분은 loss function이었다. classification 과 localization 2가지 task에 대해 어떤 task에 가중치를 두어 판단해야 할지에 대한 설계와 작은 박스와 큰 박스의 크기에 대한 오차를 어떻게 가중치를 두어 판단해야 할지에 대한 설계를 통해서 하나의 네트워크 구조로 구현하면서 정확도를 높이기 위한 노력이 보였다.
References
[1506.02640] You Only Look Once: Unified, Real-Time Object Detection

댓글남기기